
[IT동아 김예지 기자] 세계 통신사들이 만든 인공지능(AI) 모델을 평가하기 위한 벤치마크가 공개됐다. 지난 2월 25일 세계이동통신사업자연합회(GSMA)가 발표한 ‘GSMA 오픈 텔코 LLM 벤치마크(Open-Telco LLM Benchmarks)’다.
이는 지난 3월 3일부터 나흘간 스페인 바르셀로나에서 열린 세계 최대 모바일 전시회 ‘모바일 월드 콩그레스 2025(MWC 2025)’에 앞서 발표됐다. 이 벤치마크를 주도하는 기업에는 SKT, LG유플러스를 비롯해 도이치 텔레콤, 투르크셀, 화웨이 등이 있다.
벤치마크는 하드웨어 및 소프트웨어, 시스템, 기기 등의 성능을 측정 및 비교하기 위한 평가 도구다. 이번에 공개된 벤치마크는 기존의 일반적인 AI 평가 도구와 차별된다. GSMA는 통신사의 독특한 요구 사항 및 사용 사례를 반영하도록 설계됐다고 설명한다.
이는 지난 3월 3일부터 나흘간 스페인 바르셀로나에서 열린 세계 최대 모바일 전시회 ‘모바일 월드 콩그레스 2025(MWC 2025)’에 앞서 발표됐다. 이 벤치마크를 주도하는 기업에는 SKT, LG유플러스를 비롯해 도이치 텔레콤, 투르크셀, 화웨이 등이 있다.
 |
벤치마크는 하드웨어 및 소프트웨어, 시스템, 기기 등의 성능을 측정 및 비교하기 위한 평가 도구다 / 출처=셔터스톡 |
벤치마크는 하드웨어 및 소프트웨어, 시스템, 기기 등의 성능을 측정 및 비교하기 위한 평가 도구다. 이번에 공개된 벤치마크는 기존의 일반적인 AI 평가 도구와 차별된다. GSMA는 통신사의 독특한 요구 사항 및 사용 사례를 반영하도록 설계됐다고 설명한다.
GSMA 오픈 텔코 거대언어모델(LLM) 벤치마크는 기존의 LLM이 통신 관련 작업을 수행하는 데 어려움을 겪는다는 점에서 출발했다. 챗GPT, 라마, 미스트랄, 큐웬 등 AI 모델이 3GPP 사양, ITU 지침 등 표준과 정책, 네트워크 관련 기술 작업을 수행하지 못한다는 것. SKT의 텔벤치(TelBench) 연구에 따르면, 기존 LLM은 통신 고객 서비스와 기술 질의 분야에서 성과가 낮고, 업계별 용어를 다루는 데 어려움을 겪는 것으로 나타났다.
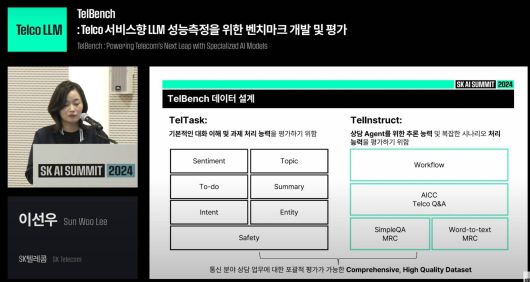 |
SKT는 텔코 LLM 성능 평가를 위한 텔벤치를 소개했다 / 출처=SKT |
지난해 SK AI 서밋에서 이선우 SKT 데이터 구축/평가 팀장은 “LLM 상담사 등 상용화 사례를 통해 어떤 기능을 우선으로 학습시켜야 하는지 인사이트를 얻을 수 있다. SKT가 만든 텔벤치는 실제 사례를 기반으로 하는 벤치마크 데이터셋을 통해 포괄적인 성능에 대한 평가가 가능하도록 설계했다”며, “비즈니스 맥락을 이해할 수 있도록 설계한 평가 데이터 ‘텔테스크(TelTask)’와 도메인 기본 역량 및 추론 능력 평가 데이터 ‘텔인스트럭트(TelInstruct)’를 바탕으로 기존 LLM을 평가한 결과, 통신 서비스명, 비즈니스 맥락을 이해하지 못했다”고 말했다.
이러한 배경에서 공개된 오픈 텔코 LLM 벤치마크는 실제 통신 문서 및 규정 준수 시나리오를 기준으로 AI 모델을 평가한다. 프레임워크가 오픈소스로 제공되는 만큼, 통신 분야에서 생성 AI를 도입하는 사업자로부터 의견이 수용된다. 예컨대, 이동통신망 운영, 고객 서비스 자동화, 네트워크 관리 등 주요 업무에서 LLM이 효과적으로 작동하는지 평가한다. 특히 통신사 데이터의 처리와 보안에 대한 적합성, 언어 다양성, 실시간 응답 속도 등도 주요 평가 항목에 포함된다.
덕분에 이는 통신 산업 전반에 걸쳐 LLM의 효율성 및 품질을 측정하는 기준이 될 것으로 기대된다. GSMA는 “통신사가 AI 솔루션을 선택하거나 기존 시스템을 최적화하는 데 중요한 지침 역할을 할 전망”이라고 말했다.
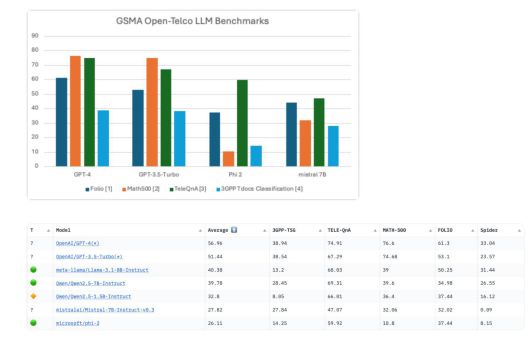 |
오픈AI의 GPT-4 및 GPT-3.5 터보 모델이 각각 평균 점수 56.96, 51.44를 획득해 가장 높은 순위를 차지했다 / 출처=GSMA 오픈 텔코 LLM 벤치마크 |
오픈 텔코 LLM 벤치마크는 ▲TeleQnA(통신 도메인 지식 및 기술적 이해) ▲3GPPTdocs 분류(표준 이해 및 문서 구문 분석) ▲MATH500(수학적 추론 및 모델링) ▲FOLIO(논리 및 추론) 등 4가지 핵심 데이터셋을 사용해 AI 모델을 평가했다.
허깅 페이스에 공개된 결과에 따르면, 오픈AI의 GPT-4 및 GPT-3.5 터보 모델이 각각 평균 점수 56.96, 51.44를 획득해 가장 높은 순위를 차지했다. 그러나 통신 표준 이해에서는 어려움이 있었다. 또한 메타의 라마 3-8B-인스트럭트 모델은 평균 점수 40.38로 통신 도메인 점수는 높았지만, 역시 표준 이해 부문에서 점수가 낮았다. 이외에 미스트랄, 마이크로소프트 Phi-2 등 소형 모델은 20점대의 낮은 점수를 기록해 통신 AI에 적합하지 않다는 결과가 나왔다.
향후 오픈 텔코 LLM 벤치마크는 4가지 데이터셋을 넘어 ▲네트워크 문제 해결 ▲에너지 효율성 ▲안전 ▲사업자 중심 사용 사례 등 주요 산업 우선순위에 따라 AI 모델을 평가함으로써 실제 통신 과제를 해결한다. 이는 오픈소스로 제공돼 폐쇄적·독점적 AI 평가 도구와 달리 공정성을 확보, 지속 개선해 나간다는 계획이다.
한편, 여기에는 몇 가지 우려도 공존한다. 먼저 AI 모델을 평가하기 위한 고품질의 데이터가 충분하지 않아 효과적인 활용이 어려울 수 있다는 점이다. 또한 평가 결과에서 높은 점수를 받더라도 실제 사례에서 발휘되는 성능과 차이를 보일 수 있다. 결국 오픈 텔코 LLM 벤치마크의 출범은 통신 산업에서 AI 모델의 성능을 개선을 위한 중요한 걸음이지만, 현실적인 접근 방식을 통해 한쪽으로 치우치지 않도록 주의하면서 동시에 꾸준한 성능 향상이 필요해 보인다.
IT동아 김예지 기자 (yj@itdonga.com)
사용자 중심의 IT 저널 - IT동아 (it.donga.com)































































