
[박찬 기자]
인공지능(AI) 스타트업 갈릴레오가 대형언어모델(LLM)을 기반으로 다른 LLM을 평가하는 새로운 평가 도구를 출시했다. 이를 통해 낮은 대기 시간, 낮은 비용, 높은 정확도로 LLM의 환각을 감지할 수 있게 됐다는 설명이다.
벤처비트는 6일(현지시간) 갈릴레오가 기업이 LLM의 정확도를 평가하는 새로운 평가 도구 '루나(Luna)'를 출시했다고 전했다.
이에 따르면 루나는 환각 감지, 상황 품질 평가, 데이터 유출 방지, 악성 프롬프트 식별과 같은 평가 작업을 수행하는 자체 소형언어모델(sLM)을 활용해 대기시간과 비용을 줄이고 정확도를 높였다.
 |
인공지능(AI) 스타트업 갈릴레오가 대형언어모델(LLM)을 기반으로 다른 LLM을 평가하는 새로운 평가 도구를 출시했다. 이를 통해 낮은 대기 시간, 낮은 비용, 높은 정확도로 LLM의 환각을 감지할 수 있게 됐다는 설명이다.
벤처비트는 6일(현지시간) 갈릴레오가 기업이 LLM의 정확도를 평가하는 새로운 평가 도구 '루나(Luna)'를 출시했다고 전했다.
이에 따르면 루나는 환각 감지, 상황 품질 평가, 데이터 유출 방지, 악성 프롬프트 식별과 같은 평가 작업을 수행하는 자체 소형언어모델(sLM)을 활용해 대기시간과 비용을 줄이고 정확도를 높였다.
비크람 채터지 갈릴레오 CEO는 "갈릴레오는 느리고 비용이 많이 들고 종종 부정확한 현재 생성 AI 평가 방법의 한계를 해결하기 위해 루나를 만들었다"라고 말했다.
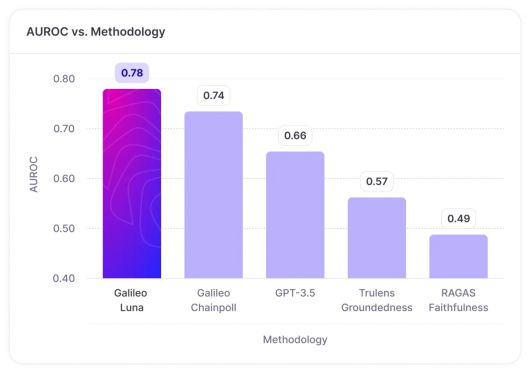
최근에는 GPT-4와 같은 LLM을 사용하여 다른 LLM 결과를 평가하는 것이 일반적인 추세로 자리잡고 있다. 특히 루나는 최고의 평가 도구를 테스트하는 벤치마크에서 기존의 모든 평가 기술을 능가하는 것으로 확인됐다.
평가 정확도와 관련하여 루나는 환각 감지 작업에서 오픈AI의 GPT-3.5를 사용하여 평가하는 것보다 18% 더 정확한 것으로 나타났다. 데이터 유출 방지, 악성 프롬프트 식별 등과 같은 평가 작업에서도 비슷한 성능을 보였다.
 |
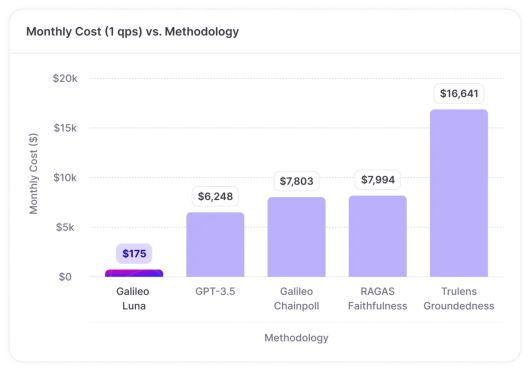
또 비용 측면에서도 연간 100만달러를 초과하는 값비싼 LLM 기반 평가를 대체할 수 있고 인간 평가에 대한 의존도를 크게 줄일 수 있다. 테스트에서 루나는 프로덕션 트래픽을 평가할 때 오픈AI의 GPT-3.5보다 97% 더 저렴한 것으로 나타났다.
 |
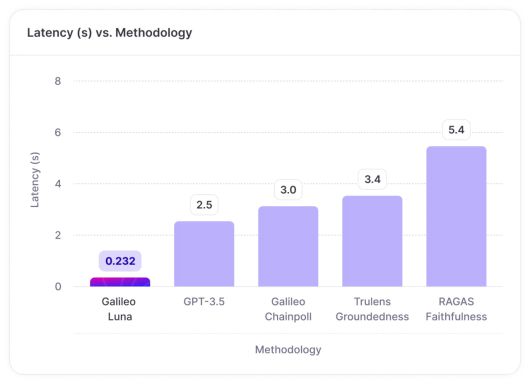
마지막으로 대기시간과 관련하여 루나는 정확성을 저하시키지 않고 밀리초 단위로 LLM 응답을 평가하도록 구축됐다. 환각 감지 작업에서 루나는 GPT-3.5를 사용하는 것보다 11배 빠른 것으로 나타났다.
 |
일반적으로 평가에는 델 응답과 비교할 '정답'으로 사용할 수 있는 사용 사례별 인간이 생성한 질문-응답 쌍의 데이터셋이 필요하다. 그러나 고품질의 테스트 세트를 만드는 것은 종종 많은 노동력과 비용이 들며, 일반적으로 인간 전문가나 GPT 모델의 참여를 필요로 한다.
그러나 루나를 사용하면 질문-정답 테스트셋 없이 사용자가 즉시 LLM 응답을 평가할 수 있다. 루나는 다양한 도메인별 데이터셋에 대해 미세조정된 사전 훈련된 평가 모델을 활용함으로써 시간과 비용이 많이 드는 사용자 정의 테스트셋 구축 프로세스를 제거했다.
또 칼릴레오의 파인튠(Fine Tune) 제품을 사용하면 루나를 고객의 특정 요구 사항에 맞게 맞춤화할 수 있으며, 제약 및 금융 서비스와 같은 산업에서 중요한 작업에 대해 95% 이상의 정확도를 달성할 수 있다. 고객 클라우드에 있는 고객 데이터로 신속하게 미세조정되어 초고정밀 맞춤형 평가 모델을 몇 분 내에 제공할 수 있다.
채터지는 "루나는 특히 월 수백만건의 쿼리를 처리하는 대규모 기업 애플리케이션에서 강력하다"며 "우리는 헬스케어, 금융, 통신 분야의 포춘 100대 기업들이 루나를 특히 유용하게 사용하는 것을 보고 있다"고 말했다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>
![가수 맹유나, 심장마비 돌연사…29세 교수 임용 앞두고 비보 [Oh!쎈 이슈]](/_next/image?url=https%3A%2F%2Fthumb.zumst.com%2F256x144%2Fhttps%3A%2F%2Fstatic.news.zumst.com%2Fimages%2F29%2F2025%2F12%2F26%2Feda5f3b658554aceb5ffad4928852296.jpg&w=384&q=100)
![크리스마스에 전해진 비보…故김영대 돌연 사망, '윤종신→정용화' 가요계 애도 물결 [엑's 이슈]](/_next/image?url=https%3A%2F%2Fthumb.zumst.com%2F256x144%2Fhttps%3A%2F%2Fstatic.news.zumst.com%2Fimages%2F108%2F2025%2F12%2F26%2Ff3d8a2f9e7734063b567b480ef23d115.jpg&w=384&q=100)
![[종합] '48세 이혼' 홍진경, 결국 속내 밝혔다…돌싱 후 첫 크리스마스에 "울다가 웃어" ('옥문아')](/_next/image?url=https%3A%2F%2Fthumb.zumst.com%2F256x144%2Fhttps%3A%2F%2Fstatic.news.zumst.com%2Fimages%2F77%2F2025%2F12%2F26%2F33c12baba89a49bc91f10d8ac607b354.jpg&w=384&q=100)




























































