
[박찬 기자]
오픈AI의 동영상 생성 인공지능(AI) '소라(Sora)'가 뛰어난 성능을 발휘할 수 있었던 것은 '비전 트랜스포머(ViT)' 아키텍처를 고도화한 결과로 알려졌다. 이는 구글이 고안한 기술로, 오픈AI는 '챗GPT'가 그랬던 것처럼 구글 기술로 먼저 제품을 내놓는 데 성공했다.
기술 전문 매체 미디엄은 최근 오픈AI의 비디오 생성 AI 모델 소라의 핵심 요소인 '시공간 패치(Spacetime Patch)' 기술을 소개했다.
이에 따르면 소라는 텍스트 프롬프트를 분석해 주제, 행동, 장소, 시간, 분위기 등 관련 키워드를 추출한다. 그다음 데이터셋에서 키워드와 일치하는 가장 적합한 동영상을 검색하고 이를 혼합하여 새로운 동영상을 만든다. 사용자의 선호도에 따라 비디오의 모양과 느낌을 수정할 수 있으며, 이미지를 기반으로 비디오를 만들거나 새로운 자료로 기존 영상을 확장도 가능하다.
 |
(사진=셔터스톡) |
오픈AI의 동영상 생성 인공지능(AI) '소라(Sora)'가 뛰어난 성능을 발휘할 수 있었던 것은 '비전 트랜스포머(ViT)' 아키텍처를 고도화한 결과로 알려졌다. 이는 구글이 고안한 기술로, 오픈AI는 '챗GPT'가 그랬던 것처럼 구글 기술로 먼저 제품을 내놓는 데 성공했다.
기술 전문 매체 미디엄은 최근 오픈AI의 비디오 생성 AI 모델 소라의 핵심 요소인 '시공간 패치(Spacetime Patch)' 기술을 소개했다.
이에 따르면 소라는 텍스트 프롬프트를 분석해 주제, 행동, 장소, 시간, 분위기 등 관련 키워드를 추출한다. 그다음 데이터셋에서 키워드와 일치하는 가장 적합한 동영상을 검색하고 이를 혼합하여 새로운 동영상을 만든다. 사용자의 선호도에 따라 비디오의 모양과 느낌을 수정할 수 있으며, 이미지를 기반으로 비디오를 만들거나 새로운 자료로 기존 영상을 확장도 가능하다.
소라는 노이즈처럼 보이는 비디오로 시작, 여러 단계를 거쳐 노이즈를 제거해 점차 비디오로 변형하는 디퓨전(Diffusion) 모델이다. 또 챗GPT와 유사하게 트랜스포머 아키텍처를 사용해 뛰어난 확장 성능을 제공한다. 즉 소라는 디퓨전 모델의 노이즈 모델링을 통한 고품질 샘플 생성과 트랜스포머의 모델링 성능을 결합한 '디퓨전 트랜스포머'다.
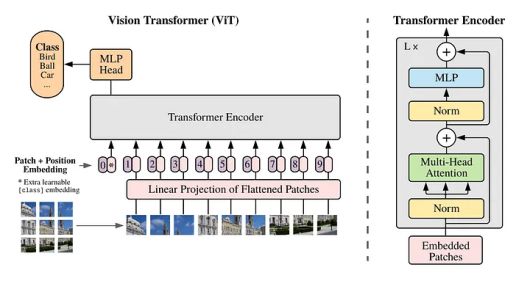 |
트랜스포머는 문장 속 단어와 같은 순차 데이터를 학습해 맥락과 의미를 추적할 수 있으며, 서로 떨어져 있는 데이터 요소들의 의미를 이해할 수 있다. 소라는 텍스트 토큰 대신 이미지를 고정 크기로 나눈 패치를 전달해 시각 데이터에서 작동하도록 트랜스포머 아키텍처를 조정한 '비전 트랜스포머'를 도입했다.
그런데 비전 트랜스포머 아키텍처는 구글 딥마인드가 2021년 아카이브에 논문으로 게재하며 처음 소개한 기술이다.
소라는 이에 따라 비디오를 패치로 변환하고 순차적으로 직렬화해 단일 시퀀스의 시공간 패치로 압축한다. 이를 통해 모델은 비디오 시퀀스 전체의 공간적, 시간적 관계를 이해할 수 있다. 이 방법을 사용하면 크기와 종횡비가 고정된 이미지 훈련 데이터를 사용하는 비전 트랜스포머와 달리 크기 조정이나 패딩과 같은 전처리 단계 없이 다양한 시각적 데이터 배열을 효율적으로 처리할 수 있다.
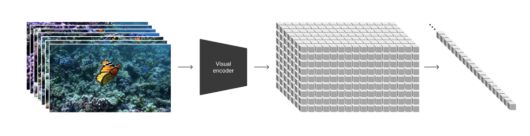 |
비디오를 조정하거나 전처리하지 않고 훈련 데이터를 원래 형식으로 사용할 수 있기 때문에 놀라운 정확도로 실제 세계를 모델링하는 방법을 배울 수 있다. 객체와 캐릭터가 3차원 공간에서 설득력 있게 움직이고 상호 작용하는 디지털 세계와 비디오를 생성할 수 있으며, 가려지거나 프레임을 벗어나는 경우에도 일관성을 유지할 수 있다.
특히 방대한 데이터셋에서 효과적인 학습이 가능해 고화질 비디오 생성 기능은 향상되지만, 다른 생성 AI에 비해 컴퓨팅 비용은 낮아진다는 강점도 가지고 있다.
 |
한편 비디오 생성 AI에서는 사실 구글이 조금 더 빠르게 움직였다. 구글은 지난 1월 '루미에르(Lumiere)'라는 모델을 발표했다.
루미에르는 텍스트나 이미지 입력으로부터 생성되는 비디오의 공간적 사실성과 시간적 일관성을 개선한 새로운 시공간 확산 모델이다. 비디오 전체를 한 프로세스로 생성하는 '시공간 U–넷(Space-Time U-Net)' 아키텍처를 도입했다. 다만 1분짜리 영상을 만드는 소라와 달리, 최대 5초 길이의 비디오 생성이 한계였다.
앞서 구글은 2022년 10월에도 당시 획기적이라고 평가받았던 비디오 생성 모델인 '이마젠 비디오(Imagen Video)'와 '페나키(Phenaki)'를 공개한 바 있다.
특히 페나키는 비디오를 픽셀 수준이 아닌 토큰으로 변환한 비디오와 텍스트 생성을 통합한 트랜스포머 기반의 모델로, 소라와 접근 방식이 유사하다. 비디오로부터 순서대로 프레임을 가져와 일정 크기의 패치 단위로 추출하고 선형 변환을 적용해 압축하는 방식이다. 더 구체적이고 긴 동영상을 만들어 준다는 점에서 주목을 끌었다.
최근에는 시공간 비전 트랜스포머 아키텍처를 기반으로 하는 비디오 이해 모델인 '비디오프리즘(VideoPrism)'을 공개하는 등 동영상 AI에 집중하고 있었다.
하지만 결과적으로 완성된 동영상 생성 AI를 먼저 내놓은 쪽은 오픈AI였다.
이런 사례가 처음은 아니다. 구글은 2017년 '트랜스포머' 논문을 발표, 현재 대형언어모델(LLM)의 기반을 만들었다. 이어 '람다'라는 챗봇도 제작했지만, 내부에서 챗봇에 의식이 있다는 폭로가 나온 뒤 공개를 미뤘다.
그 가운데 오픈AI는 2022년 10월 챗GPT를 내놓으며 생성 AI의 기준으로 자리 잡았다. 구글이 '바드'를 출시한 것은 이로부터 5개월 뒤인 2023년 3월이다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>



![크리스마스에 전해진 비보…故김영대 돌연 사망, '윤종신→정용화' 가요계 애도 물결 [엑's 이슈]](/_next/image?url=https%3A%2F%2Fthumb.zumst.com%2F256x144%2Fhttps%3A%2F%2Fstatic.news.zumst.com%2Fimages%2F108%2F2025%2F12%2F26%2Ff3d8a2f9e7734063b567b480ef23d115.jpg&w=384&q=100)



























































