
[박우용 편집위원] [디지털포스트(PC사랑)=박우용 편집위원 ]
데이터 센터의 구조적 위기와 CXL의 필연성
2025년 현재, 인공지능(AI), 특히 생성형 AI(Generative AI)와 파라미터 수 조(Trillion) 단위의 초거대 언어 모델(LLM)이 주도하는 현대 컴퓨팅 환경은 지난 반세기 동안 IT 산업을 지탱해 온 '폰 노이만(Von Neumann)' 아키텍처를 붕괴 직전의 위기로 몰아넣고 있습니다. 중앙처리장치(CPU)와 메모리가 물리적으로 분리되어 있고 버스(Bus)를 통해 데이터를 주고받는 이 전통적인 구조는 연산 장치(Logic)의 혁신 속도를 데이터 전송 속도가 따라가지 못하는 구조적 한계에 봉착했습니다. 엔비디아(NVIDIA)의 GPU로 대변되는 가속기의 연산 성능은 무어의 법칙을 초월하는 속도로 발전했으나, 이 연산 장치에 데이터를 공급해야 할 메모리 시스템은 여전히 과거의 물리적, 구조적 제약에 갇혀 있기 때문입니다.
 |
삼성전자는 지난 2023년 업계 최초로 레드햇(Red Hat)과 CXL(Compute Express Link) 메모리 동작 검증에 성공했다. |
데이터 센터의 구조적 위기와 CXL의 필연성
2025년 현재, 인공지능(AI), 특히 생성형 AI(Generative AI)와 파라미터 수 조(Trillion) 단위의 초거대 언어 모델(LLM)이 주도하는 현대 컴퓨팅 환경은 지난 반세기 동안 IT 산업을 지탱해 온 '폰 노이만(Von Neumann)' 아키텍처를 붕괴 직전의 위기로 몰아넣고 있습니다. 중앙처리장치(CPU)와 메모리가 물리적으로 분리되어 있고 버스(Bus)를 통해 데이터를 주고받는 이 전통적인 구조는 연산 장치(Logic)의 혁신 속도를 데이터 전송 속도가 따라가지 못하는 구조적 한계에 봉착했습니다. 엔비디아(NVIDIA)의 GPU로 대변되는 가속기의 연산 성능은 무어의 법칙을 초월하는 속도로 발전했으나, 이 연산 장치에 데이터를 공급해야 할 메모리 시스템은 여전히 과거의 물리적, 구조적 제약에 갇혀 있기 때문입니다.
이러한 불균형은 소위 '메모리 장벽(Memory Wall)'이라 불리는 현상으로 구체화됩니다. 이는 프로세서의 연산 속도와 메모리의 데이터 전송 속도 간의 격차가 극심해짐에 따라, 아무리 빠른 AI 가속기를 도입하더라도 데이터가 제때 공급되지 않아 시스템 전체의 성능이 메모리 대역폭에 의해 제한되는 병목 현상을 의미합니다. 현재 AI 학습(Training) 시장은 HBM(High Bandwidth Memory)이라는 초고대역폭 메모리가 장악하며 이 문제를 해결하려 노력하고 있습니다. HBM은 TSV(실리콘 관통 전극) 기술을 통해 수천 개의 입출력(I/O) 통로를 뚫어 대역폭을 극대화한 '프리미엄 엔진' 역할을 수행합니다.
그러나 AI 모델의 파라미터가 기하급수적으로 증가하는 현시점에서, HBM만으로는 감당할 수 없는 두 가지 결정적인 한계가 드러나고 있습니다. 첫째는 용량(Capacity)의 한계입니다. 물리적인 적층 수와 다이 크기의 제약으로 인해 HBM은 용량 대비 비용이 매우 높으며, 단일 GPU 패키지 내에 탑재할 수 있는 총 용량에 물리적 한계가 존재합니다. 둘째는 자원의 비효율성, 즉 '고립된 메모리(Stranded Memory)' 문제입니다.
기존 서버 아키텍처에서 CPU와 메모리는 1:1로 강하게 결합(Tightly Coupled)되어 있습니다. 각 서버는 자신에게 할당된 로컬 메모리에만 접근할 수 있으며, 외부의 자원을 직접적으로 끌어다 쓸 수 없는 폐쇄적인 구조를 가집니다. 이로 인해 A 서버는 연산 자원이 부족하여 작업을 수행하지 못하는 반면 메모리는 남아돌고, 인접한 B 서버는 연산 자원은 충분하지만 메모리가 부족하여 작업이 중단되는 '자원 불일치(Resource Mismatch)' 현상이 빈번하게 발생합니다. 통계적으로 데이터 센터의 메모리 이용률은 50%를 밑도는 경우가 많으며, 이는 막대한 자본적 지출(CAPEX)과 운영 비용(OPEX)의 낭비를 의미합니다. 이러한 비효율성은 데이터 센터의 총 소유 비용(TCO)을 급격히 증가시키는 주범으로 지목되고 있습니다.
이러한 난제를 해결하기 위해 인텔, 삼성전자, SK하이닉스, AMD 등 글로벌 반도체 거인들이 결성한 컨소시엄을 통해 등장한 기술적 해법이 바로 CXL(Compute Express Link)입니다. CXL은 단순히 메모리 용량을 늘리는 인터페이스가 아닙니다. 물리적으로는 PCIe(PCI Express) 5.0 이상의 고속 인터페이스를 공유하지만, 논리적으로는 전혀 다른 계층을 형성하여 메모리를 시스템의 중심 자원으로 재정의하는 '메모리 중심 컴퓨팅(Memory-Centric Computing)'의 핵심 기술입니다. CXL은 서로 다른 기종의 장치들이 메모리를 공유하고 캐시 일관성을 유지할 수 있도록 지원함으로써, 데이터 센터를 거대한 하나의 '자원 풀(Resource Pool)'로 전환시키려 하고 있습니다.
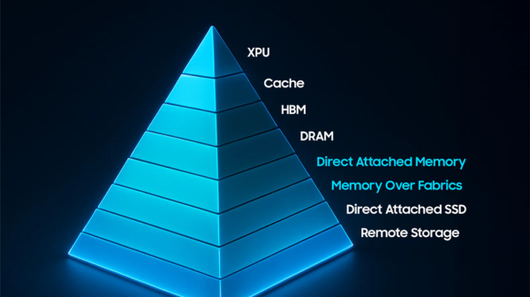 |
CXL 디바이스를 활용한 두 단계의 메모리 계층을 추가한 예시. 사진=삼성전자 |
CXL 아키텍처 심층 분석: PCIe 위에 쌓아 올린 혁신
시스템 아키텍트의 관점에서 CXL을 해부해보면, 이는 PCIe라는 초고속 데이터 고속도로 위에 '캐시 일관성(Cache Coherency)'이라는 정교한 신호등 및 통제 체계를 얹은 것과 유사합니다. CXL의 기술적 정수는 물리적 계층(PHY)은 PCIe를 그대로 사용하여 기존 하드웨어 생태계와의 호환성을 유지하면서도, 상위 프로토콜 계층에서 독자적인 다중화(Multiplexing) 기술을 구현했다는 점에 있습니다. 이를 통해 CXL은 단순한 I/O 장치를 넘어 메모리와 프로세서가 대등하게 소통할 수 있는 언어를 제공합니다.
플렉스 버스(Flex Bus)와 링크 협상 메커니즘
CXL은 시스템 부팅 시 '플렉스 버스(Flex Bus)' 기술을 통해 링크의 정체성을 결정합니다. 링크 트레이닝(Link Training) 초기 단계에서 호스트와 디바이스는 '대체 프로토콜 협상(APN: Alternate Protocol Negotiation)' 과정을 수행합니다. 이 과정에서 호스트와 디바이스의 컨트롤러는 서로의 기능(Capability)을 확인합니다. 만약 양쪽 컨트롤러가 모두 CXL을 지원한다는 것이 확인되면 링크는 CXL 모드로 전환되어 고유의 프로토콜을 사용하게 됩니다. 반면, 한쪽이라도 CXL을 지원하지 않는 경우 시스템은 즉시 표준 PCIe 모드로 폴백(Fallback)하여 하위 호환성을 완벽하게 보장합니다. 이러한 설계는 물리적으로 기존 PCIe 슬롯과 동일한 폼팩터를 사용하여, 기존 인프라를 그대로 활용하면서도 CXL 디바이스를 점진적으로 도입할 수 있게 하는 핵심적인 전략입니다.
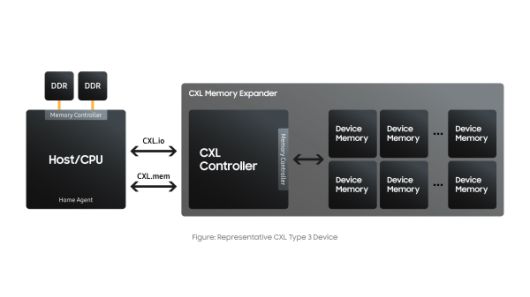 |
CXL의 중요한 기능은 직접 연결된 CPU 메모리와 CXL 디바이스의 메모리 간에 메모리 일관성을 유지하는 것으로, 그것은 호스트와 CXL 디바이스가 같은 데이터를 원활하게 확인할 수 있다는 것을 의미한다. CXL 호스트에는 CXL.io와 CXL.mem 트랜잭션을 사용해서 연결된 메모리에 일관되게 액세스하는 관리자 역할의 홈 에이전트가 있다. 사진=삼성전자 |
세 가지 핵심 프로토콜의 하모니
CXL은 용도에 따라 세 가지 프로토콜을 단일 물리적 링크 위에서 다중화하여 혼합 사용합니다. 각 프로토콜은 고유한 채널을 통해 전송되며, 시스템의 요구사항에 따라 유기적으로 작동합니다.
ㆍ CXL.io (Input/Output): 장치의 발견(Discovery), 구성(Configuration), 초기화, 인터럽트 처리, 오류 보고 등을 담당합니다. 이는 PCIe의 트랜잭션 계층(Transaction Layer)을 기반으로 하며 거의 동일한 기능을 수행합니다. 모든 CXL 장치는 필수적으로 CXL.io를 구현해야 하며, 이를 통해 시스템은 장치를 인식하고 관리할 수 있습니다.
ㆍ CXL.cache (Cache Coherency): 가속기(Device)가 호스트 CPU의 캐시 메모리에 일관성 있게 접근(Snoop)할 수 있게 합니다. 이를 통해 가속기는 CPU의 데이터를 메인 메모리로 복사하는 과정(Copy overhead) 없이, 낮은 지연 시간으로 CPU 캐시 내의 최신 데이터를 직접 읽어갈 수 있습니다. 이는 특히 CPU와 가속기가 데이터를 빈번하게 주고받아야 하는 이종 컴퓨팅(Heterogeneous Computing) 환경에서 필수적인 기능입니다.
ㆍCXL.mem (Memory Access): 메모리 확장의 핵심 프로토콜입니다. 호스트 CPU가 디바이스에 장착된 메모리를 마치 시스템의 메인 DDR 메모리처럼 로드/스토어(Load/Store) 명령어로 직접 접근할 수 있게 합니다. 이는 기존 스토리지 방식의 블록 단위 접근이 아닌, 바이트(Byte) 단위의 직접 접근을 가능하게 하여 지연 시간을 획기적으로 단축시킵니다.
플릿(Flit) 아키텍처와 지연 시간 최적화 (L-Opt Mode)
CXL이 PCIe와 차별화되는 가장 큰 기술적 특징은 데이터 전송 단위인 '플릿(Flit: Flow Control Unit)'의 설계에 있습니다. PCIe가 가변 길이 패킷(TLP)을 사용하여 오버헤드가 가변적이고 예측이 어려운 것과 달리, CXL은 고정된 크기의 플릿을 사용하여 처리 효율을 극대화하고 예측 가능한 지연 시간(Deterministic Latency)을 제공합니다.
68바이트 플릿 (CXL 1.1/2.0): 64바이트 데이터와 2바이트 헤더, 2바이트 CRC로 구성됩니다. 이는 현대 CPU의 표준 캐시 라인 크기인 64바이트와 정확히 일치하도록 설계되었습니다. 불필요한 패딩이나 데이터 분할 없이 캐시 라인 하나를 온전히 전송할 수 있어 오버헤드를 최소화하고 효율성을 극대화합니다.
256바이트 플릿 (CXL 3.0/4.0): CXL 3.0부터는 기반이 되는 PCIe 6.0의 신호 방식이 NRZ(Non-Return-to-Zero)에서 PAM-4(Pulse Amplitude Modulation 4-level)로 변경되었습니다. PAM-4는 한 번의 클럭 사이클에 2비트를 전송하여 대역폭을 두 배로 늘리지만, 신호 대 잡음비(SNR)가 낮아져 비트 오류율(BER)이 급격히 증가한다는 단점이 있습니다. 이를 보정하기 위해 강력한 FEC(Forward Error Correction) 기술이 필수적으로 요구되었고, FEC 블록 단위를 맞추기 위해 플릿 크기를 256바이트로 키웠습니다.
그러나 플릿 크기가 커지면 전송 및 버퍼링 시간이 길어져, 지연 시간(Latency)에 극도로 민감한 메모리 접근에는 불리할 수 있습니다. 256바이트를 모두 수신하고 FEC를 수행한 뒤 CRC를 확인하는 과정은 메모리 로드 명령에 치명적인 지연을 초래할 수 있기 때문입니다. 여기서 시스템 아키텍트가 주목해야 할 기술은 '지연 시간 최적화 모드(L-Opt Mode: Latency-Optimized Mode)'입니다.
CXL 3.0은 이를 해결하기 위해 CRC를 128바이트 단위로 쪼개어 배치하는 설계를 도입했습니다. 일반적인 모드에서는 플릿의 끝에 CRC가 위치하지만, L-Opt 모드에서는 플릿 중간에 CRC가 삽입됩니다. 이를 통해 수신 측 컨트롤러는 256바이트 플릿 전체가 도착하기를 기다리지 않고, 전반부 128바이트만 도착해도 해당 부분의 CRC 체크를 수행하고 즉시 처리를 시작할 수 있습니다. 만약 오류가 없다면 데이터는 곧바로 상위 계층으로 전달되며, 이는 고속 인터커넥트의 물리적 페널티를 논리적 설계로 극복한 탁월한 엔지니어링의 예시입니다. 다만, FEC가 필요한 수준의 오류가 발생할 경우, 시스템은 NOP(No Operation) 삽입을 통해 파이프라인을 잠시 멈추고 FEC 복구 절차를 수행하여 데이터 무결성을 보장합니다.
 |
CXL Pooled Memory(Niagara 2.0) 설루션을 활용한 Memory Centric AI Machine. |
데이터 이동의 패러다임 전환: DMA에서 Load/Store로
CXL이 단순한 인터페이스 확장을 넘어 '혁명'이라 불리는 이유는 데이터 이동 방식의 근본적인 변화 때문입니다. 기존의 PCIe 기반 SSD나 가속기는 데이터를 처리하기 위해 복잡한 DMA(Direct Memory Access) 과정을 거쳐야 했습니다. CPU가 DMA 엔진을 설정하고, 호스트 메모리에서 디바이스 메모리로 데이터를 복사한 후, 완료 인터럽트를 받고 컨텍스트 스위칭(Context Switching)을 수행하는 일련의 과정은 높은 지연 시간(Latency)과 소프트웨어 오버헤드를 유발했습니다. 이는 데이터의 양이 적을 때는 큰 문제가 되지 않았으나, 테라바이트급 데이터를 실시간으로 처리해야 하는 AI 워크로드에서는 시스템 성능을 저하시키는 치명적인 비효율이 됩니다.
Zero-Copy의 실현과 HDM 디코더
반면, CXL.mem을 사용하는 CXL 메모리는 'Load/Store 시맨틱'을 사용합니다. CPU는 별도의 드라이버 호출이나 명시적인 데이터 복사 명령 없이, 메모리 주소 포인터를 역참조(Dereference)하는 것만으로 원격 CXL 메모리에 접근합니다. 이는 데이터 복사가 불필요한 Zero-Copy 환경을 구현하여 애플리케이션의 성능을 극대화합니다. 이러한 투명한 접근이 가능한 이유는 CXL 장치 내부와 호스트 브리지에 위치한 HDM(Host-Managed Device Memory) 디코더 덕분입니다.
HDM 디코더를 통한 주소 변환 과정은 다음과 같이 정교하게 이루어집니다.
시스템 매핑 (System Mapping): 부팅 시 시스템 펌웨어(BIOS/UEFI)
는 ACPI(Advanced Configuration and Power Interface) 테이블 중 하나인 CEDT(CXL Early Discovery Table)를 참조합니다. 펌웨어는 이 테이블에 정의된 CFMWS(CXL Fixed Memory Window Structures) 정보를 바탕으로 CXL 메모리 영역을 호스트 물리 주소(HPA: Host Physical Address) 공간에 할당합니다.
하드웨어 라우팅 (Hardware Routing): CPU가 해당 HPA 주소로 읽기/쓰기 명령을 내리면, 호스트 브리지(Host Bridge)의 디코더는 미리 설정된 인터리빙(Interleaving) 규칙을 확인합니다. 여러 CXL 장치에 데이터가 분산되어 있을 경우, 특정 주소 비트를 해시(Hash) 연산하여 요청을 보낼 적절한 CXL 포트(Root Port)를 결정하고 패킷을 라우팅합니다.
주소 변환 (Address Translation, HPA → DPA): 요청을 받은 CXL 장치 내부의 HDM 디코더는 들어온 호스트 물리 주소(HPA)를 장치 내부의 실제 DRAM 셀을 가리키는 장치 물리 주소(DPA: Device Physical Address)로 변환합니다.
이 모든 과정은 하드웨어 레벨에서 밀리초(ms)가 아닌 나노초(ns) 단위로 수행되므로, 운영체제(OS)나 애플리케이션의 수정 없이도 대용량 메모리를 즉시 활용할 수 있습니다. 이는 대규모 인메모리 데이터베이스(Redis, SAP HANA)나 추천 시스템의 임베딩 테이블(Embedding Table)과 같이 방대한 데이터 중 일부를 무작위로 읽어야 하는(Random Read) 워크로드에서 기존 스토리지 방식 대비 압도적인 성능 우위를 제공합니다.
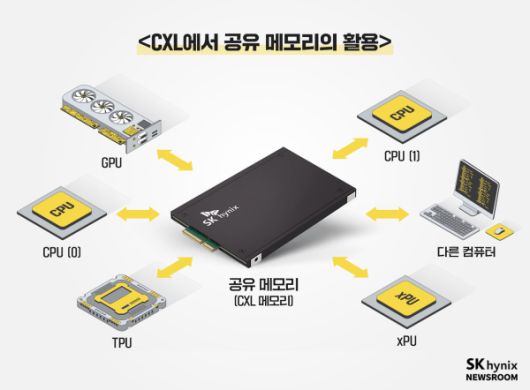 |
SK하이닉스 CXL 2.0 메모리 활용 예시. 사진=SK하이닉스 |
캐시 일관성의 진화: Bias Mode에서 Back-Invalidation으로
다중 호스트 환경에서 데이터의 무결성을 보장하는 캐시 일관성(Cache Coherency) 프로토콜 또한 CXL 3.0에서 크게 진화했습니다. 초기 CXL 2.0은 '바이어스 모드(Bias Mode)'를 사용하여 메모리 페이지의 소유권을 관리했습니다. 페이지가 '호스트 바이어스' 상태이면 CPU가 일관성을 관리하고, '디바이스 바이어스' 상태이면 가속기가 관리하는 방식입니다. 하지만 소유권을 변경하기 위해 '바이어스 플립(Bias Flip)'을 수행하는 과정에서 높은 지연 시간이 발생하여, 호스트와 디바이스가 빈번하게 데이터를 공유하는 시나리오에는 부적합했습니다.
CXL 3.0은 이를 '백-인밸리데이션(Back-Invalidation)' 방식으로 대체했습니다. 이 방식에서는 호스트나 디바이스가 데이터를 수정하려 할 때, 해당 데이터를 캐싱하고 있는 다른 주체에게 스눕 인밸리데이트(Snoop Invalidate) 신호를 보내 강제로 캐시 라인을 무효화시킵니다. 호스트는 스눕 필터(Snoop Filter)를 통해 어떤 장치가 어떤 데이터를 가지고 있는지 추적하므로, 불필요한 브로드캐스팅 없이 해당 장치에게만 선별적으로 신호를 보낼 수 있습니다. 이는 디바이스가 별도의 모드 변경 절차 없이 항상 최신 상태를 유지하게 하는 대칭적 일관성(Symmetric Coherency)을 구현하여, 진정한 의미의 '메모리 풀링(Memory Pooling)'과 다중 호스트 간 '메모리 공유(Memory Sharing)'를 기술적으로 완성시켰습니다.
2025년 산업 지형도: CXL 4.0과 토털 솔루션 경쟁
2025년 12월 현재, CXL 기술은 실험실을 벗어나 본격적인 상용화 단계에 진입했습니다. 특히 2025년 11월 CXL 컨소시엄이 공식 발표한 CXL 4.0 표준은 기술의 성숙도를 증명하며 산업계의 기대감을 고조시키고 있습니다.
CXL 4.0: 대역폭의 퀀텀 점프와 패브릭 혁신
CXL 4.0은 PCIe 7.0 PHY를 기반으로 하며, 전송 속도가 기존 CXL 3.0(64 GT/s) 대비 두 배 향상된 PCIe 7.0 기반의 128 GT/s를 지원합니다. 이는 x16 레인 기준으로 양방향 약 512GB/s의 대역폭을 제공하여, CXL 링크가 HBM의 대역폭에 근접하도록 만듭니다. 이러한 대역폭의 증가는 CXL이 단순한 용량 확장을 넘어 고성능 연산 데이터의 주 통로가 될 수 있음을 의미합니다.
또한, CXL 4.0은 구리선의 물리적 전송 거리 한계를 극복하기 위한 광학 인터커넥트(Optical Interconnect) 최적화가 포함되어, 랙(Rack) 단위를 넘어선 데이터 센터 규모의 메모리 통합을 준비하고 있습니다. 이는 물리적으로 떨어진 서버들이 하나의 거대한 메모리 풀을 광속으로 공유하는 GFAM(Global Fabric Attached Memory) 시대를 예고합니다. GFAM 환경에서는 PBR(Port-Based Routing) 스위치를 통해 최대 4,096개의 노드를 메쉬(Mesh)나 링(Ring) 구조로 연결할 수 있으며, 데이터 복사 없이 다수의 호스트가 단일 데이터셋에 접근하는 진정한 제로 카피 클러스터를 구현할 수 있습니다.
삼성전자와 SK하이닉스의 전략: 제2의 HBM을 향하여
메모리 반도체 양강인 삼성전자와 SK하이닉스는 CXL을 단순한 부품이 아닌 차세대 플랫폼으로 정의하고, 각기 다른 강점을 내세워 시장을 공략하고 있습니다.
 |
삼성전자 CXK 메모리 모듈. 사진=삼성전자 |
삼성전자 (하드웨어 중심의 토털 솔루션): 삼성전자는 CXL을 '제2의 HBM'으로 정의하고 가장 공격적인 하드웨어 로드맵을 전개하고 있습니다. 2025년 말 CXL 3.1 표준을 지원하는 차세대 CMM-D(CXL Memory Module - DRAM) 출시를 목표로 하고 있으며, 256GB 및 128GB 용량의 E3.S 폼팩터 제품 양산에 돌입했습니다. 또한, 다수의 모듈을 장착할 수 있는 랙 마운트형 솔루션인 CMM-B(Box)를 통해 테라바이트급 용량을 제공합니다. CMM-B는 최대 24개의 E3.S CMM-D 장치를 탑재하여 총 24TiB의 용량을 지원하며, 최대 8개의 호스트가 이를 공유할 수 있습니다. 삼성은 자체 개발한 관리 플랫폼인 'Cognos'를 통해 CMM-B 내의 메모리 자원을 시각화하고 관리하는 소프트웨어 솔루션까지 함께 제공하여 하드웨어 생태계를 주도하고 있습니다. 낸드 플래시를 결합하여 용량을 더욱 확장한 하이브리드 솔루션(CMM-H) 역시 삼성전자의 차별화된 포트폴리오 중 하나입니다.
SK하이닉스 (소프트웨어 융합 및 최적화): SK하이닉스는 HBM 시장의 지배력을 바탕으로 CXL과의 시너지를 강조하며 소프트웨어 기술력에 집중합니다. 특히 리눅스 커널에 통합된 HMSDK(Heterogeneous Memory SDK)는 CXL의 태생적 약점인 지연 시간을 소프트웨어적으로 극복하는 핵심 무기입니다. 이 SDK는 '가중치 인터리빙(Weighted Interleaving)' 기술을 구현하여, 대역폭이 높은 로컬 메모리(DDR)와 대역폭이 상대적으로 낮은 CXL 메모리에 데이터를 분산 저장할 때 그 비율을 지능적으로 조절합니다. 예를 들어 로컬 메모리와 CXL 메모리의 대역폭 비율에 맞춰 데이터를 3:1이나 4:1로 분산함으로써 전체 대역폭 효율을 최적화합니다. 또한 DAMON(Data Access MONitor) 기능을 활용하여 자주 쓰이는 데이터(Hot Data)는 빠른 로컬 메모리로, 덜 쓰이는 데이터(Cold Data)는 CXL로 보내는 페이지 이동(Page Migration)을 자동화하여 시스템 전체 성능 저하를 방지합니다. SK하이닉스는 이러한 기능을 최신 리눅스 커널 메인라인(v6.x 후반대)에 통합시키며 소프트웨어 생태계 표준을 주도하고 있습니다.
생태계의 확장, 컨트롤러와 패브릭
CXL 생태계에는 메모리 제조사 외에도 중요한 플레이어들이 존재합니다. Astera Labs는 2025년 OCP 글로벌 서밋에서 'COSMOS' 플랫폼을 공개하며 CXL 링크의 물리적 상태를 실시간으로 모니터링하고 관리하는 솔루션을 선보였으며, 이는 대규모 클라우드 인프라를 운영하는 하이퍼스케일러(Hyperscaler)들에게 필수적인 신뢰성을 제공합니다. 또한 Montage Technology와 Marvell 등은 CXL 3.0/4.0 스위치 칩셋을 통해 다대다(Many-to-Many) 연결을 지원하는 패브릭 구성을 현실화하고 있습니다. 이들의 기술 성숙도는 메모리가 특정 서버에 종속되지 않고 네트워크상의 공유 자원이 되는 시대를 앞당기는 트리거가 될 것입니다.
CXL은 HBM 경쟁자 아닌 상호 보완적 계층
결론적으로 CXL은 HBM의 경쟁자가 아닙니다. 그들은 상호 보완적인 계층형 메모리(Tiered Memory) 구조의 핵심 축입니다. AI 시대를 맞이하여 메모리 계층은 다음과 같이 재편되고 있습니다.
Tier 1 (HBM): AI 학습 및 초고속 연산을 위한 최고 대역폭(Bandwidth) 엔진. 가장 비싸고 용량이 작으며, GPU와 가장 가까운 곳에 위치합니다.
Tier 2 (DDR5): OS 구동 및 지연 민감형 애플리케이션을 위한 최저 지연 시간(Latency) 메모리. CPU에 직접 연결되어 범용 연산을 담당합니다.
Tier 3 (CXL): AI 추론(Inference)의 KV Cache, 인메모리 DB의 웜 데이터(Warm Data)를 위한 무한한 확장성(Capacity) 저장소. 필요에 따라 용량을 유연하게 늘릴 수 있습니다.
CXL 메모리의 지연 시간(약 170~250ns)은 로컬 DDR(약 80~100ns) 대비 2~3배 높지만, 이는 원격 NUMA 노드(다른 소켓의 CPU 메모리)에 접근하는 지연 시간(약 140~150ns)과 유사한 수준입니다. 따라서 CXL 메모리를 별도의 특수 장치가 아닌 'CPU가 없는 NUMA 노드(CPU-less NUMA Node)'로 인식시킴으로써, 기존 OS 스케줄러와 소프트웨어 생태계를 수정 없이 그대로 활용할 수 있다는 점은 CXL의 가장 강력한 무기입니다.
2025년 이후, CXL 4.0과 패브릭 기술이 성숙해짐에 따라 메모리는 더 이상 서버 섀시(Chassis) 안에 갇힌 수동적인 부품이 아닌, 네트워크상에서 공유되고 동적으로 할당되며 스스로 연산까지 수행(Processing near Memory)하는 독립적인 '시스템'으로 진화할 것입니다. 이것이 바로 CXL이 '형(HBM)'과는 다른 길을 걷지만, 결국 형만큼이나 중요한, 혹은 형이 할 수 없는 거대한 확장을 담당할 '아우'가 될 수밖에 없는 이유입니다. CXL은 HBM이 쏘아 올린 AI라는 로켓이 우주 정거장을 짓고 더 먼 곳으로 나아갈 수 있게 하는 생명선이자 보급로가 될 것입니다. 한국 반도체 기업들이 HBM에서의 성공 방정식을 CXL에서도 재현하며, 단순한 '메모리 벤더'를 넘어 '토털 컴퓨팅 솔루션 프로바이더'로 도약할 수 있을지 전 세계가 주목하고 있습니다.
<저작권자 Copyright ⓒ 디지털포스트(PC사랑) 무단전재 및 재배포 금지>


































































