
[박찬 기자]
텍스트를 이미지 데이터로 변환해 장문 컨텍스트를 적은 토큰으로 처리한다는 딥시크의 획기적인 연구 결과에 의문ㅌ이 제기됐다.
일본 도호쿠대학교와 중국과학원 연구진은 20일(현지시간) AI가 긴 문서나 방대한 대화를 처리하는 데 겪는 롱 컨텍스트 병목 문제를 해결하기 위해 딥시크가 제안한 새로운 텍스트 압축 기법 '딥시크-OCR'이 실제로는 기대만큼 효과적이지 않다는 연구 논문을 온라인 아카이브를 통해 공개했다.
지난 10월 공개된 딥시크-OCR은 텍스트를 이미지로 변환해 AI가 처리해야 할 토큰 수를 크게 줄이는 방식으로, 장문 처리 능력을 획기적으로 개선할 방법으로 주목받았다. 딥시크는 "시각 기반 콘텍스트 압축을 통해 토큰 수를 7~20배까지 줄일 수 있다"라며, 대규모·복잡 문서를 다루는 데 유망한 해법이 될 수 있다고 주장했다.
 |
텍스트를 이미지 데이터로 변환해 장문 컨텍스트를 적은 토큰으로 처리한다는 딥시크의 획기적인 연구 결과에 의문ㅌ이 제기됐다.
일본 도호쿠대학교와 중국과학원 연구진은 20일(현지시간) AI가 긴 문서나 방대한 대화를 처리하는 데 겪는 롱 컨텍스트 병목 문제를 해결하기 위해 딥시크가 제안한 새로운 텍스트 압축 기법 '딥시크-OCR'이 실제로는 기대만큼 효과적이지 않다는 연구 논문을 온라인 아카이브를 통해 공개했다.
지난 10월 공개된 딥시크-OCR은 텍스트를 이미지로 변환해 AI가 처리해야 할 토큰 수를 크게 줄이는 방식으로, 장문 처리 능력을 획기적으로 개선할 방법으로 주목받았다. 딥시크는 "시각 기반 콘텍스트 압축을 통해 토큰 수를 7~20배까지 줄일 수 있다"라며, 대규모·복잡 문서를 다루는 데 유망한 해법이 될 수 있다고 주장했다.
그러나 이번 연구에 따르면 딥시크-OCR의 성능은 이미지 내용을 정확히 읽어내는 시각적 이해력보다는, AI가 이미 학습해 둔 문장 구조와 단어 패턴 같은 '언어적 사전 지식(language priors)'에 지나치게 의존하고 있는 것으로 나타났다.
연구진은 딥시크가 공개한 성능 지표가 이런 한계를 충분히 드러내지 못해 "오해를 불러올 수 있다"라고 지적했다.
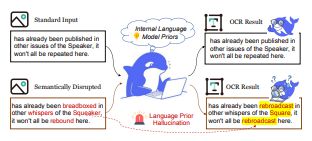 |
그 결과, 문맥이나 언어적 힌트가 사라지자 딥시크-OCR의 정확도는 약 90%에서 20% 수준으로 크게 떨어졌다. 이는 이 모델이 내세운 시각 기반 인식 성능의 상당 부분이 실제로는 언어적 추론에 의존해 유지되고 있음을 보여준다.
컨텍스트 길이를 점점 늘여가며 진행한 스트레스 테스트에서는 약 1만개의 텍스트 토큰 수준에서 모델 성능이 사실상 무너지는 현상도 확인됐다. 연구진은 이에 대해 "광학 압축 기법이 장문 컨텍스트 처리 한계를 해결하기는커녕, 오히려 문제를 더 심화시킬 수 있다"라고 지적했다.
AI 업계에서는 장문 컨텍스트 문제를 차세대 성능 도약의 핵심 과제로 보고 있다. 대규모 문서 분석, 장시간 대화, 복잡한 코드베이스 이해 등에서 한계를 극복하면, AI 시스템의 활용 범위가 확장하고 에이전트의 성능이 크게 향상할 수 있기 때문이다. 이에 따라 전 세계 기업과 연구 기관이 다양한 해법을 모색 중이다.
하지만, 일부 전문가들은 딥시크-OCR을 실패한 접근으로 보기는 어렵다며, 상황에 따라 장단점이 갈릴 수 있다고 평가한다.
중국과학기술대 출신으로 현재 AI 스타트업을 운영 중인 리보제 박사는 "거의 판독이 불가능한 필사본처럼 정보가 불완전한 경우에는, 모델이 학습한 지식을 활용하는 방식이 오히려 도움이 될 수 있다"라고 설명했다.
다만, "글자가 또렷하게 인쇄된 문서에서는 이런 특성이 오히려 정확도를 떨어뜨리는 요인이 될 수 있다"라고 덧붙였다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>

![성매매 요구 거절에 격분…종로 여관에 불 질러 7명 목숨 앗아갔다[그해 오늘]](/_next/image?url=https%3A%2F%2Fthumb.zumst.com%2F256x144%2Fhttps%3A%2F%2Fstatic.news.zumst.com%2Fimages%2F24%2F2026%2F01%2F21%2Fa150eeb1bf52474a9ab984919d90c1ca.jpg&w=384&q=100)
































































