
[박찬 기자]
구글이 대형언어모델(LLM)이 복잡한 추론 과제에서 환각에 빠지거나 장기 계획을 제대로 수행하지 못하는 문제를 해결할 수 있는 새로운 학습 기법을 제시했다.
구글은 16일(현지시간) 기존의 '다음 토큰 예측' 방식 대신, 모델 내부에서 이뤄지는 '생각의 흐름' 자체를 강화 학습(RL)으로 조정하는 새로운 방법 '내부 강화 학습(Internal RL)'을 온라인 아카이브를 통해 공개했다.
현재 LLM은 방대한 데이터로 사전 학습한 자기회귀(autoregressive) 모델을 RL로 사후 학습하는 방식으로 뛰어난 성과를 내고 있다.
 |
구글이 대형언어모델(LLM)이 복잡한 추론 과제에서 환각에 빠지거나 장기 계획을 제대로 수행하지 못하는 문제를 해결할 수 있는 새로운 학습 기법을 제시했다.
구글은 16일(현지시간) 기존의 '다음 토큰 예측' 방식 대신, 모델 내부에서 이뤄지는 '생각의 흐름' 자체를 강화 학습(RL)으로 조정하는 새로운 방법 '내부 강화 학습(Internal RL)'을 온라인 아카이브를 통해 공개했다.
현재 LLM은 방대한 데이터로 사전 학습한 자기회귀(autoregressive) 모델을 RL로 사후 학습하는 방식으로 뛰어난 성과를 내고 있다.
그러나, 이런 구조에는 한계가 있다. 모델이 항상 한번에 한 토큰씩 행동을 탐색하며 학습하기 때문에, 보상이 드문(sparse reward) 환경이나 수십단계에 걸쳐 계획이 필요한 장기 과제에서는 학습 효율이 급격하게 떨어진다. 연구진은 토큰 단위로 무작위 탐색을 할 경우, 올바른 다단계 해법을 우연히 찾아낼 확률은 '100만분의 1'에 불과하다고 설명한다.
핵심은 모델이 단순히 실수를 하는 것이 아니라, 잘못된 추상화 수준에서 문제를 풀고 있다는 데 있다. 세부 단계에 지나치게 집착하다가 길을 잃거나, 반대로 전체 목표를 놓친 채 엉뚱한 방향으로 진행하는 일이 반복된다는 것이다.
이런 한계를 극복하기 위해 학계는 오래전부터 '계층적 강화 학습(Hierarchical RL, HRL)에 주목해 왔다. HRL은 개별 토큰이나 세부 행동을 직접 다루는 대신, 여러 단계를 묶은 고수준의 하위 목표(서브루틴)를 학습하는 접근법이다.
하지만, 실제로는 의미 있는 서브루틴을 자동으로 찾아내는 것 자체가 매우 어려운 문제였다. 그 결과 많은 HRL 기법이 실제 행동과 무관한 패턴으로 수렴하거나, 실질적인 문제 해결로 이어지지 못했다. 희소한 보상을 다루기 위해 고안된 GRPO 같은 최신 RL 알고리즘조차도, 복잡한 환경에서는 장기 계획과 실행을 효과적으로 연결하지 못하며 한계를 드러냈다.
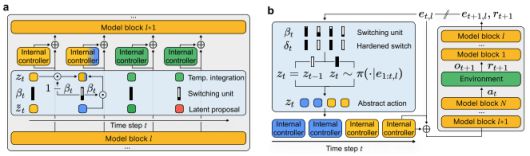
구글 연구진의 핵심 통찰은 간단하다. 최신 자기회귀 모델은 이미 복잡한 다단계 행동을 수행하는 방법을 내부적으로 알고 있다는 것이다. 다만 이 능력은 모델의 잔차 스트림(residual stream), 즉 네트워크 내부 표현에 숨어 있어 지금까지의 학습 방식에서는 외부의 RL 신호가 이를 제대로 끌어내지 못했다는 점을 지적했다.
이를 위해 연구진은 '메타컨트롤러(meta-controller)'라는 내부 신경망을 도입했다. 이 컨트롤러는 출력 토큰을 직접 바꾸는 대신, 모델 중간 계층의 내부 활성화에 개입해 모델을 특정 '유용한 상태'로 유도한다. 이렇게 방향만 잡아주면, 기본 모델은 사전 학습 과정에서 이미 익힌 패턴을 활용해 필요한 세부 행동을 스스로 이어서 생성하게 된다는 설명이다.
메타컨트롤러는 사람의 라벨링 없이 자기 지도 학습으로 훈련한다. 전체 행동 시퀀스를 분석한 뒤, 그 행동을 가장 잘 설명하는 숨겨진 고수준 의도를 거꾸로 추론하는 방식이다. 내부 RL 단계에서 다음 토큰 예측이 아니라, 해결로 이어지는 고수준 행동 자체를 학습 목표로 삼는다.
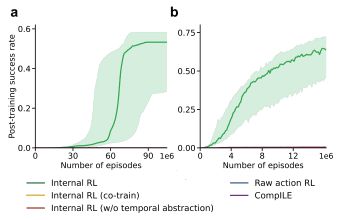 |
결과는 인상적이었다. GRPO나 CompILE 같은 기존 방법들이 100만 에피소드 안에서도 과제를 해결하지 못했지만, 내부 RL은 훨씬 적은 학습 횟수로도 높은 성공률을 기록했다.
이는 메타컨트롤러가 세부적인 단계 대신, 고수준 목표를 먼저 선택함으로써 탐색해야 할 경우의 수를 크게 줄였고, 어떤 결정이 성공으로 이어졌는지를 빠르고 정확하게 학습할 수 있었기 때문이다.
주목할 점은 기본 모델을 '동결(frozen)'한 상태에서 메타컨트롤러만 학습했을 때 가장 좋은 성과가 나왔다는 점이다. 기본 모델과 컨트롤러를 동시에 학습하면 의미 있는 추상화가 이뤄지지 않았지만, 이미 사전 학습한 모델을 동결한 상태에서는 사람이 따로 알려주지 않아도 실제 하위 목표가 바뀌는 순간과 정확히 맞아떨어지는 내부 전환 구조를 스스로 찾아냈다.
현재 AI 업계는 장황한 사고 사슬(CoT) 출력을 통해 추론 능력을 끌어내는 데 주력하고 있다. 그러나 구글의 이번 연구는 토큰으로 드러나지 않는 '내부 추론'이 더 효율적일 수 있다는 것을 보여준다.
연구진은 내부 RL이 장기 계획과 복잡한 추론이 필요한 작업, 나아가 자율 에이전트와 실제 로봇 제어까지 확장 가능한 경로를 열 수 있다고 봤다.
특히, 코드 생성처럼 논리적 설계와 문법적 정확성이 동시에 필요한 작업에서 큰 틀의 논리와 구조는 자유롭게 탐색하면서도 실제 토큰 생성은 안정적으로 유지하는 새로운 해법이 될 수 있다고 강조했다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>


































































