
[박찬 기자]
메타가 사람의 개입 없이도 AI가 스스로 문제를 만들고 해결하며 진화할 수 있음을 보여주는 연구를 공개했다.
메타 슈퍼인텔리전스 랩스(MSL)는 12일(현지시간) 훈련 데이터나 인간 주석 없이, 오직 외부 검색 엔진만을 활용해 추론·검색 능력을 스스로 끌어올리는 자기 진화(Self-evolving) AI 프레임워크 '닥터 제로(Dr. Zero, DeepResearch-Zero)'를 온라인 아카이브에 공개했다.
그동안 자기 진화형 AI는 수학이나 코딩처럼 범위가 좁은 분야에만 주로 활용돼 왔다. 또 다양한 질문을 다뤄야 하는 개방형 검색 AI는 사람이 만든 데이터와 지도 학습(supervised learning)이 필수였다.
 |
메타가 사람의 개입 없이도 AI가 스스로 문제를 만들고 해결하며 진화할 수 있음을 보여주는 연구를 공개했다.
메타 슈퍼인텔리전스 랩스(MSL)는 12일(현지시간) 훈련 데이터나 인간 주석 없이, 오직 외부 검색 엔진만을 활용해 추론·검색 능력을 스스로 끌어올리는 자기 진화(Self-evolving) AI 프레임워크 '닥터 제로(Dr. Zero, DeepResearch-Zero)'를 온라인 아카이브에 공개했다.
그동안 자기 진화형 AI는 수학이나 코딩처럼 범위가 좁은 분야에만 주로 활용돼 왔다. 또 다양한 질문을 다뤄야 하는 개방형 검색 AI는 사람이 만든 데이터와 지도 학습(supervised learning)이 필수였다.
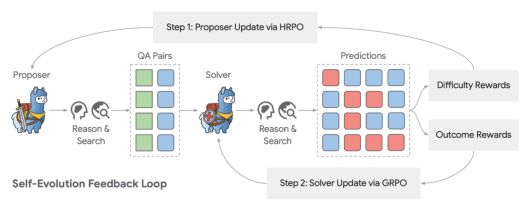
닥터 제로는 이런 한계를 넘어, 학습 데이터나 예시, 사람의 주석 없이도 스스로 문제를 만들고 풀면서 복잡한 다단계 추론 능력을 키운 것이 특징이다.
이 시스템의 핵심은 '제안자(Proposer)'와 '해결자(Solver)'가 서로 상호작용하는 피드백 구조다.
제안자는 해결자의 학습을 돕기 위해 점점 더 다양하고 어려운 질문을 만들어 내고, 해결자는 그 질문을 풀면서 능력을 키운다. 해결자가 성장할수록 제안자는 너무 쉽지도, 불가능하지도 않은 문제를 제시해야 더 높은 보상을 받게 되며, 이 과정에서 사람이 개입하지 않아도 자연스럽게 학습 단계가 조정되는 자동 커리큘럼이 만들어진다. 연구진은 이를 서로를 자극하며 함께 발전하는 교사와 학생의 관계에 비유했다.
데이터 없이 스스로 진화하는 AI의 가장 큰 장애물은 막대한 계산 비용이었다. 기존의 그룹 상대 정책 최적화(GRPO) 방식은 하나의 질문에 대해 여러 답변을 생성해야 했기 때문에, 여러 단계를 거쳐야 하는 다중 턴 검색 에이전트에서는 효율이 크게 떨어졌다.
이를 해결하기 위해 닥터 제로는 질문의 구조와 복잡도를 고려해 학습 효율을 높인 HRPO(Hop-Grouped Relative Policy Optimization) 기법을 새롭게 도입했다.
HRPO는 질문을 추론 단계(hop) 수에 따라 묶어, 구조가 비슷한 질문들끼리 공통 기준선을 설정하는 방식이다. 이 덕분에 여러번 답변을 뽑아 비교하는 중첩 샘플링 없이도 학습이 가능해졌고, 학습 과정은 더 안정적이고 효율적이 됐다는 설명이다.
결과적으로 계산 자원 사용은 크게 줄이면서도 성능은 유지하거나 오히려 향상하는 효과를 거뒀다고 강조했다.
닥터 제로는 보상 설계에서도 기존과는 다른 접근을 택했다. 제안자가 무작정 어려운 문제만 내면, 해결자가 아예 접근하지 못해 학습이 이뤄지지 않기 때문이다. 이에 연구진은 난이도와 검증 가능성의 균형을 핵심으로 한 보상 체계를 도입했다.
해결자가 모든 질문을 맞히면 해당 문제를 너무 쉬운 문제로 판단해 보상을 낮추고, 반대로 모든 답변을 틀리면 지나치게 어려운 문제로 간주한다. 가장 높은 보상은 해결자가 충분히 도전할 수 있으면서도 실제로 풀 수 있는 수준의 질문에 주어진다. 이 구조를 통해 제안자는 학습 효과를 극대화하는 최적의 문제를 스스로 만들어 내는 방향으로 진화하게 된다.
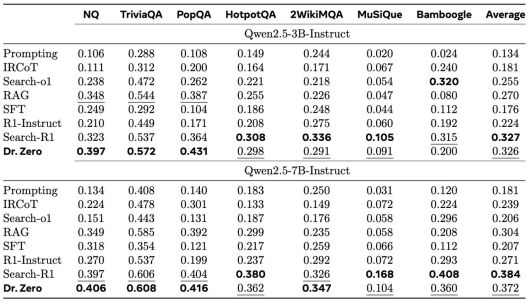 |
벤치마크 결과 (사진=arXiv) |
실험 결과는 인상적이다. 닥터 제로는 '핫스팟QA'와 '2위키MQA(WikiMQA)'처럼 복잡한 다중 홉 질의응답(QA) 벤치마크에서, 사람의 데이터로 학습된 완전 지도 학습 기반 검색 에이전트와 대등하거나 그보다 뛰어난 성능을 기록했다.
특히 2위키MQA에서는 최대 14.1%의 성능 향상을 보였으며, '큐원2.5-7B' 모델 기준으로 지도 학습 모델인 '서치-R1(0.347)'을 넘어서는 평균 점수 0.372를 달성했다.
연구진은 "고품질 데이터 확보가 점점 어려워짐에 따라, 데이터 없는 자기 진화(data-free self-evolution)가 유망한 패러다임으로 떠오르고 있다"라고 전했다.
따라서 이번 연구는 AI가 스스로 질문을 생성하고 학습하는 '데이터 프리 자기 진화' 방식이 실질적인 대안이 될 수 있음을 보여준다고 강조했다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>


































































