
[박찬 기자]
대형언어모델(LLM)의 고질적인 한계로 지적돼 온 '기억 관리' 문제를 근본적으로 해결하려는 학습법이 나왔다. 핵심은 장기 기억과 단기 대화를 따로 관리하지 않고, AI가 스스로 무엇을 기억하고, 필요할 때 꺼내 쓰고, 요약하거나 버릴지를 한번에 판단하도록 만든 것이다. 즉, 복잡한 규칙이나 외부 장치에 의존하지 않고 AI가 직접 기억을 관리하게 한 것이다.
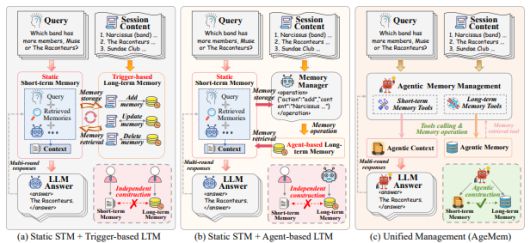
알리바바와 중국 우한대학교 연구진은 12일 장기 기억과 단기 기억을 분리해 관리하던 기존 방식에서 벗어나, 기억 관련 작업을 언어 생성과 같은 '행동 공간(action space)' 안에 통합한 새로운 프레임워크 '에이지멤(Agentic Memory, AgeMem)'을 온라인 아카이브를 통해 공개했다.
이 프레임워크에서는 모델이 단계마다 일반 텍스트를 생성할지 또는 기억을 추가·수정·삭제하거나 요약·필터링·검색하는 '도구 호출'을 실행할지를 스스로 판단해 선택한다.
 |
대형언어모델(LLM)의 고질적인 한계로 지적돼 온 '기억 관리' 문제를 근본적으로 해결하려는 학습법이 나왔다. 핵심은 장기 기억과 단기 대화를 따로 관리하지 않고, AI가 스스로 무엇을 기억하고, 필요할 때 꺼내 쓰고, 요약하거나 버릴지를 한번에 판단하도록 만든 것이다. 즉, 복잡한 규칙이나 외부 장치에 의존하지 않고 AI가 직접 기억을 관리하게 한 것이다.
알리바바와 중국 우한대학교 연구진은 12일 장기 기억과 단기 기억을 분리해 관리하던 기존 방식에서 벗어나, 기억 관련 작업을 언어 생성과 같은 '행동 공간(action space)' 안에 통합한 새로운 프레임워크 '에이지멤(Agentic Memory, AgeMem)'을 온라인 아카이브를 통해 공개했다.
이 프레임워크에서는 모델이 단계마다 일반 텍스트를 생성할지 또는 기억을 추가·수정·삭제하거나 요약·필터링·검색하는 '도구 호출'을 실행할지를 스스로 판단해 선택한다.
LLM 에이전트는 한번에 처리할 수 있는 컨텍스트 길이가 제한돼 있어, 긴 시간에 걸친 추론에 약하다는 문제가 있다. 그동안은 장기 기억을 벡터 데이터베이스에 저장하고, 단기 기억은 슬라이딩 윈도우나 요약 규칙으로 관리하는 등 경험에 의존한 방식이 주로 사용됐다.
하지만 이런 접근은 장기 기억과 단기 기억이 따로 최적화돼 서로 잘 맞물리지 않고, 드물지만 중요한 정보가 빠질 가능성이 크며, 별도의 제어 장치가 필요해 시스템 비용과 복잡성이 커진다는 한계를 안고 있었다.
기존처럼 장기 기억(LTM)과 단기 기억(STM)을 따로 분리해 규칙이나 외부 시스템으로 관리하는 대신, 에이지멤은 기억 관련 행동을 언어 생성과 같은 수준의 '선택 가능한 행동'으로 통합했다.
즉, 모델은 매 순간 그냥 답변을 생성할지, 기억을 저장(ADD), 수정(UPDATE), 삭제(DELETE) 할지, 필요한 기억을 검색(RETRIEVE) 하거나 대화를 요약(SUMMARY) 하거나 불필요한 내용을 걸러낼지(FILTER)를 스스로 판단한다.
이 방식의 장점은 AI가 언제 기억해야 하고, 언제 잊어야 하는지 학습을 통해 익힌다는 점이다. 그 결과 긴 시간에 걸친 작업에서도 맥락을 더 잘 유지하고, 불필요한 정보로 컨텍스트가 넘치는 문제를 줄일 수 있다는 설명이다.
훈련 방식도 눈에 띈다. 연구진은 3단계로 나뉜 점진적 강화 학습 방식을 적용했다.
1단계에서는 에이전트가 일상적인 대화와 상호작용을 하면서, 나중에 필요할 수 있는 정보를 장기 기억에 저장하고 관리하는 법을 배운다. 이 단계에서는 대화가 자연스럽게 이어지며 단기 컨텍스트도 함께 쌓인다.
2단계에서는 단기 컨텍스트를 한번 비운 뒤, 꼭 필요하지 않은 정보들이 섞여 들어오는 상황을 만든다. 에이전트는 이 환경에서 요약과 필터링을 활용해 중요한 내용만 남기고 불필요한 정보는 걸러내는 방식으로 단기 기억을 조절한다.
3단계에서는 핵심 질문이 주어지고, 에이전트는 장기 기억을 검색해 필요한 정보를 불러온 뒤 단기 컨텍스트를 다시 정리하며 답변을 생성한다. 이 과정에서 장기 기억은 처음부터 끝까지 유지되고, 단기 기억만 단계 사이에서 초기화되기 때문에, 모델이 실제로 오래된 정보를 기억하고 활용해야 하는 상황이 자연스럽게 만들어진다.
보상 설계도 기존 방식보다 정교하다. 연구진은 단순히 "정답을 맞혔는가"만 보지 않고, 세 가지 요소를 동일한 비중으로 평가했다. 먼저 답변이 얼마나 정확하고 유용한지를 따지는 과제 보상이 있고, 단기 기억을 얼마나 잘 압축하면서도 질문과 관련된 정보를 유지했는지를 평가하는 컨텍스트 보상이 있다. 여기에 장기 기억에 저장된 정보의 품질과 실제로 얼마나 잘 활용됐는지를 측정하는 메모리 보상을 더 했다.
또 컨텍스트 길이가 한도를 넘을 때는 패널티를 부과해, 에이전트가 기억을 효율적으로 쓰도록 유도했다. 이런 학습을 위해 연구진은 여러 실행 경로를 묶어 상대적으로 성과를 비교하는 단계별(Step-wise) 그룹 상대 정책 최적화(GRPO) 변형 기법을 적용했다.
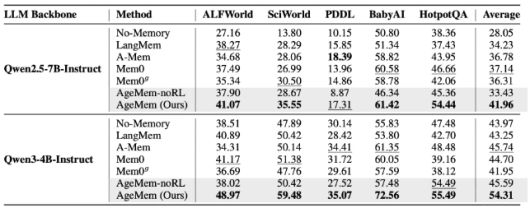 |
실험 결과는 뚜렷했다. 'ALFWorld' 'SciWorld' 'BabyAI' 'PDDL' 계획 문제, 'HotpotQA' 등 5개 장기 추론 벤치마크 전반에서 에이지멤은 기존 메모리 증강 에이전트들을 꾸준히 앞섰다.
'큐원 2.5-7B-인스트럭트' 기반에서는 평균 점수 41.96으로 최고 성능을 기록했고, '큐원3-4B-인스트럭트' 기반에서는 54.31로 가장 성능이 좋았던 기존 베이스라인을 크게 상회했다. HotpotQA에서 평가한 장기 기억 품질 지표도 모든 비교 모델보다 높게 나타났다.
단기 기억 도구의 실효성도 확인됐다. 요약과 필터링을 활용한 설정은 성능 저하 없이 프롬프트 길이를 약 3~5% 줄이는 효과를 보였다. 또 구성 요소를 하나씩 제거하는 실험에서도 장기 기억 도구, 강화학습 적용, 단기 기억 도구가 각각 독립적으로 성능 향상에 기여한다는 점이 드러났다.
이처럼 에이지멤은 에이전트 시스템의 기억은 두개의 외부 하위 시스템이 아니라 학습된 정책의 일부로 처리돼야 한다는 점을 보여주고 있다.
저장, 검색, 요약 및 필터링을 명시적인 도구로 만들고 언어 생성과 함께 학습함으로써 에이전트가 언제 기억하고 언제 잊어야 하는지, 그리고 장기간에 걸쳐 맥락을 효율적으로 관리하는 방법을 익힐 수 있다는 결론이다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>



![유재석 "♥나경은이 많이 하는 말...'왜 대답을 안 해?'" 폭풍 공감 (틈만나면)[전일야화]](/_next/image?url=https%3A%2F%2Fthumb.zumst.com%2F256x144%2Fhttps%3A%2F%2Fstatic.news.zumst.com%2Fimages%2F108%2F2026%2F01%2F14%2F966ec6b17bc94eff83b004e5a97f457c.jpg&w=384&q=100)

























































