
엔비디아가 200억달러(약 29조원)를 투자해 기술 라이선스 계약을 체결한 인공지능(AI) 반도체 설계 스타트업 '그로크'. 그로크의 가치는 특유의 반도체 설계 기술에 있습니다. 그래픽처리장치(GPU), 텐서처리장치(TPU) 등 기존 AI 칩과 달리 고대역폭메모리(HBM) 의존도를 크게 줄였습니다.
그로크의 핵심 기술 LPU, GPU와 차이점은
그로크는 지난달 24일(현지시간) 블로그를 통해 "엔비디아와 비독점적 라이선스 계약을 체결했다"고 밝혔습니다. 계약의 일부로 그로크 창업자 조너선 로스, 사장 서니 마드라 등 핵심 인력이 엔비디아에 합류했습니다. 엔비디아는 그로크가 개발한 언어처리유닛(LPU) 기술을 사용할 수 있게 됩니다.
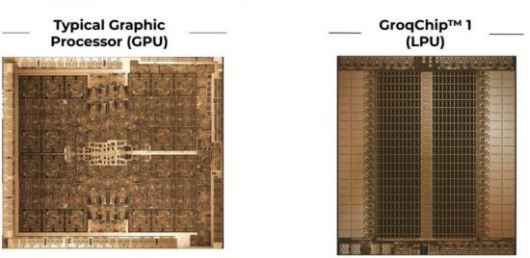
그로크는 미국의 AI 칩 설계 스타트업으로, LPU라는 독특한 칩을 개발해 왔습니다. LPU가 기존의 GPU, TPU 등 AI 칩과 차별화된 부분은 메모리에 있습니다. LPU는 다른 칩처럼 HBM을 이용해 외장 메모리를 연결하는 대신, 칩 내부에 있는 메모리를 활용하기 때문이지요.
그로크의 핵심 기술 LPU, GPU와 차이점은
 |
기존 인공지능(AI) 칩과는 차별화된 그로크의 언어처리유닛(LPU). 그로크 |
그로크는 지난달 24일(현지시간) 블로그를 통해 "엔비디아와 비독점적 라이선스 계약을 체결했다"고 밝혔습니다. 계약의 일부로 그로크 창업자 조너선 로스, 사장 서니 마드라 등 핵심 인력이 엔비디아에 합류했습니다. 엔비디아는 그로크가 개발한 언어처리유닛(LPU) 기술을 사용할 수 있게 됩니다.
그로크는 미국의 AI 칩 설계 스타트업으로, LPU라는 독특한 칩을 개발해 왔습니다. LPU가 기존의 GPU, TPU 등 AI 칩과 차별화된 부분은 메모리에 있습니다. LPU는 다른 칩처럼 HBM을 이용해 외장 메모리를 연결하는 대신, 칩 내부에 있는 메모리를 활용하기 때문이지요.
칩 외부 대신 내부에 메모리 탑재
AI 가속기는 막대한 AI 데이터를 담아둘 메모리가 필요합니다. 엔비디아나 구글은 이 문제를 칩 외부에 HBM을 연결해 해결해 왔습니다. 삼성전자, SK하이닉스 등 국내 메모리 기업들이 호황을 맞이한 것도 GPU, TPU 등에 들어갈 HBM 수요가 폭증했기 때문입니다.
하지만 엔비디아나 구글과는 다른 메모리 전략을 택한 기업들도 있습니다. 주로 그로크를 포함한 AI 스타트업들이 연구 중인데, 이들 회사는 칩 외부가 아닌 내부에 탑재된 메모리 S램(SRAM)을 사용합니다. 칩의 연산 처리 장치, 즉 '코어' 바로 옆에 연결돼 데이터 송신 속도가 빠릅니다.
그로크의 LPU는 HBM 없이도 충분한 데이터 용량과 송신 속도를 확보할 수 있습니다. 그로크는 LPU 기술 매뉴얼에서 "S램을 활용한 그로크의 메모리 대역폭(송신 속도)은 초당 80테라바이트"라며 "일반 GPU의 HBM은 초당 약 8테라바이트의 대역폭에 불과해, (LPU는) 최대 10배의 속도 우위를 보장하고 별도의 메모리 칩이 필요 없다는 장점도 있다"고 주장합니다.
AI 가속기는 막대한 AI 데이터를 담아둘 메모리가 필요합니다. 엔비디아나 구글은 이 문제를 칩 외부에 HBM을 연결해 해결해 왔습니다. 삼성전자, SK하이닉스 등 국내 메모리 기업들이 호황을 맞이한 것도 GPU, TPU 등에 들어갈 HBM 수요가 폭증했기 때문입니다.
 |
일반적인 그래픽처리장치(GPU)와 그로크 LPU의 차이점은 내부에 메모리 S램을 연결해 데이터 송신 속도가 빠르다는 점이다. 그로크 LPU 내부에 S램이 블록처럼 가지런히 배열된 모습. 그로크 |
하지만 엔비디아나 구글과는 다른 메모리 전략을 택한 기업들도 있습니다. 주로 그로크를 포함한 AI 스타트업들이 연구 중인데, 이들 회사는 칩 외부가 아닌 내부에 탑재된 메모리 S램(SRAM)을 사용합니다. 칩의 연산 처리 장치, 즉 '코어' 바로 옆에 연결돼 데이터 송신 속도가 빠릅니다.
그로크의 LPU는 HBM 없이도 충분한 데이터 용량과 송신 속도를 확보할 수 있습니다. 그로크는 LPU 기술 매뉴얼에서 "S램을 활용한 그로크의 메모리 대역폭(송신 속도)은 초당 80테라바이트"라며 "일반 GPU의 HBM은 초당 약 8테라바이트의 대역폭에 불과해, (LPU는) 최대 10배의 속도 우위를 보장하고 별도의 메모리 칩이 필요 없다는 장점도 있다"고 주장합니다.
다루기 어렵고 확장성 제한된다는 한계
그러나 S램에도 단점은 있습니다. 가장 큰 문제는 당장 S램 기반 칩들이 컴퓨터 공학자들에게 익숙하지 않다는 것입니다. 반면 엔비디아는 AI에 최적화된 소프트웨어 'CUDA(쿠다)'를 보유해 초기 AI 칩 경쟁에서 압도적 우위를 차지했습니다. 오늘날 AI 가속기 시장의 약 90%를 엔비디아 GPU가 장악하고 있습니다.
또 다른 문제는 반도체 공정에 있습니다. 현재 최신 컴퓨터 칩은 2~3나노미터(㎚) 선단 공정으로 제작되지요. 하지만 선단 공정에서 S램의 안정성이 약해 칩 내부에 촘촘히 배열하기 어려워집니다. 공정이 미세화할수록 S램의 집적도도 높아져야 외부 메모리를 완전히 대체할 텐데, 갑자기 브레이크가 걸린 셈입니다.
 |
최신 EUV 노광기 덕분에 현재 컴퓨터칩의 생산 노드는 2~3나노미터(㎚)대까지 축소됐지만, S램을 이 공정에 배열하기는 힘들다. ASML |
이와 관련, 벨기에 반도체 연구 시설 IMEC 소속 그리트 헬링스 소장은 지난해 반도체 전문 매체 '세미엔지니어링'과의 인터뷰에서 "현재 상황으로는 S램을 고도화할 여유 공간이 별로 없다"며 "S램 핀의 길이를 줄이면 그만큼 높이를 늘려야 한다. 선단 공정을 도입해도 S램의 밀도는 충분히 늘어나지 못한다는 뜻"이라고 전했습니다.
"GPU보다 훨씬 효율적인 AI 칩 될 가능성"
이런 한계에도 불구하고, 최근 들어 S램을 향한 투자가 점차 활발해지고 있습니다. 그로크뿐만이 아닙니다. S램의 선구자격 업체인 영국 그래프코어는 2024년 손정의 회장이 이끄는 소프트뱅크에 인수됐고, 현재 새로운 AI 반도체를 설계하고 있습니다. 지난달 11일에는 인텔이 또 다른 S랩 스타트업 삼바노바 인수 절차의 마무리 단계에 있다는 보도가 나왔습니다.
만일 S램이 이런 걸림돌들을 해결한다면 LPU가 생성형 AI 서비스의 기반이 되는 거대언어모델(LLM) 추론에 최적화한 AI 반도체로 올라설 잠재력이 있습니다. 미국 테크 전문 업체 '실리콘 앵글'은 "LPU 같은 칩들은 GPU보다 훨씬 효율적으로 AI 추론 업무를 수행할 가능성이 있다"라며 "그 이유는 HBM 대신 S램으로 AI 성능을 최적화했기 때문이다. S램은 HBM보다 전력 소모가 훨씬 적다"고 강조했습니다.
임주형 기자 skepped@asiae.co.kr
<ⓒ투자가를 위한 경제콘텐츠 플랫폼, 아시아경제(www.asiae.co.kr) 무단전재 배포금지>

































