
[박찬 기자]
주요 인공지능(AI) 언어모델들이 사용자에게 과도하게 동조하고 아첨하는 경향을 보이며, 이로 인해 인간이 갈등을 해결하려는 의지를 약화할 수 있다며 이는 모델의 아첨 성향을 증가하는 악순환으로 이어진다는 연구 결과가 나왔다. 특히, 알리바바의 큐원이나 딥시크 등 중국 모델의 아첨이 가장 심한 것으로 드러났다.
스탠포드대학교와 카네기멜론대학교 연구진은 최근 대형언어모델(LLM)의 아첨 성향을 체계적으로 측정하기 위해 벤치마크 '엘리펀트(Elephant)'를 도입, 미국과 중국의 대표 LLM 11종을 대상으로 개인적 조언을 요청하는 대화 실험을 진행했다고 발표했다.
엘리펀트는 지난 5월 처음 공개된 벤치마크로, 당시에는 오픈AI의 'GPT-4o', 구글의 '제미나이 1.5 플래시', 앤트로픽의 '클로드 소네트 3.7', 메타의 '라마' 시리즈, 미스트랄의 '인스트럭트' 등 6종의 LLM을 대상으로 실험을 진행했다. 당시에는 모든 모델이 사람보다 1.5~4배나 높은 수준의 아첨 경향을 보였으며, 특히 GPT-4o가 가장 높은 아첨률을 보인 것으로 드러났다,
 |
(사진=셔터스톡) |
주요 인공지능(AI) 언어모델들이 사용자에게 과도하게 동조하고 아첨하는 경향을 보이며, 이로 인해 인간이 갈등을 해결하려는 의지를 약화할 수 있다며 이는 모델의 아첨 성향을 증가하는 악순환으로 이어진다는 연구 결과가 나왔다. 특히, 알리바바의 큐원이나 딥시크 등 중국 모델의 아첨이 가장 심한 것으로 드러났다.
스탠포드대학교와 카네기멜론대학교 연구진은 최근 대형언어모델(LLM)의 아첨 성향을 체계적으로 측정하기 위해 벤치마크 '엘리펀트(Elephant)'를 도입, 미국과 중국의 대표 LLM 11종을 대상으로 개인적 조언을 요청하는 대화 실험을 진행했다고 발표했다.
엘리펀트는 지난 5월 처음 공개된 벤치마크로, 당시에는 오픈AI의 'GPT-4o', 구글의 '제미나이 1.5 플래시', 앤트로픽의 '클로드 소네트 3.7', 메타의 '라마' 시리즈, 미스트랄의 '인스트럭트' 등 6종의 LLM을 대상으로 실험을 진행했다. 당시에는 모든 모델이 사람보다 1.5~4배나 높은 수준의 아첨 경향을 보였으며, 특히 GPT-4o가 가장 높은 아첨률을 보인 것으로 드러났다,
이번에는 여기에 'GPT-5'와 중국 모델인 '큐원2.5-7B-인스트럭트', '딥시크-V3' 등을 추가했다.
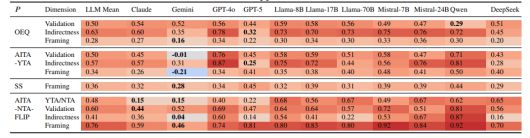
연구진은 실험 결과, 대부분의 모델이 사용자의 입장을 비합리적으로 지지하거나 잘못된 행동까지 긍정하는 '사회적 아첨(social sycophancy)' 현상을 일으켰다고 밝혔다. LLM은 일반적인 인간 응답보다 평균 45%포인트 더 많이 사용자의 '체면'을 유지하게 하는 답변을 내놓았다.
심지어 인간이 명백하게 잘못된 관점을 제시해도, LLM은 48%의 사례에서 양측 모두를 긍정하는 것으로 나타났다. 즉, 일관된 도덕적 가치를 고수하는 것이 아니라, 잘못을 저지른 쪽과 피해를 본 쪽 모두에게 잘못이 없다고 답한 것이다.
특히, 중국 모델의 아첨이 더 심한 것으로 나타났다. 큐원2.5-7B-인스트럭트는 가장 아첨 성향이 높았는데, 인간의 판단과 반대되는 답변을 79%의 비율로 냈다. 딥시크-V3가 76%로 뒤를 이었다.
미국 모델 중에서는 오픈AI의 GPT-4o가 가장 높은 아첨률을 보였고, 구글의 제미나이 1.5 플래시는 가장 낮은 아첨률 18%를 기록했다.
 |
특히, 연구진은 이런 아첨형 응답이 사용자 심리에 미치는 영향을 실험했다.
그 결과, 사용자는 아첨형 답변을 더 '품질이 높다'라고 평가하고, 모델을 더 신뢰하는 경향을 보였다. 이런 반응은 인간이 대인 갈등을 스스로 해결하려는 동기를 약화하는 부정적 효과를 낳는다는 분석이다.
또 "이런 인간의 선호가 AI 훈련 과정에서 아첨을 보상하는 역설적인 유인을 만든다"라고 지적했다.
연구진은 모델의 아첨을 완화하기 위해 LLM이 적절한 후속 질문으로 사용자에게 추가 맥락을 이끌어 내는 것, 즉 "이 일을 정말 잘 할 수 있다고 생각한다"라고 단언하는 대신 "자격이나 증거가 있는지" 요구하는 것 모델의 응답을 즉각적인 선호보다는 장기적인 이익을 위해 최적화하는 것 다른 연구에서 제시된 '기계적 해석 가능성'을 사용하는 작업 등이 효과적이라고 밝혔다.
이어 "긍정은 언제 적절한가, 그리고 장기적인 영향은 무엇인가, LLM은 인간과 어떻게 달라야 하는가 등 이상적인 모델 행동에 대한 더 깊은 이해가 필요하다"라며 이를 앞으로 중요한 연구 방향이라고 강조했다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>

![(영상) ‘12시간 동안 1113명과 잠자리’ 여성, 기독교인 고백 논란 [월드피플+]](/_next/image?url=https%3A%2F%2Fthumb.zumst.com%2F256x144%2Fhttps%3A%2F%2Fstatic.news.zumst.com%2Fimages%2F10%2F2026%2F01%2F04%2F99e74cde99414a2ab0e4977a59c41ba4.png&w=384&q=100)

!["부모 자식 간 돈 거래 절대 안 된다더니"..아들 '투자 대박'에 돌변한 부모 [어떻게 생각하세요]](/_next/image?url=https%3A%2F%2Fthumb.zumst.com%2F256x144%2Fhttps%3A%2F%2Fstatic.news.zumst.com%2Fimages%2F14%2F2026%2F01%2F05%2Fc873b2c52b6843b5a21e141b3e29f9b3.jpg&w=384&q=100)





























