
[박찬 기자]
'액체 신경망'으로 유명한 리퀴드 AI가 휴대폰과 노트북, 단일 GPU 인스턴스부터 웨어러블 및 기타 임베디드 기기에 이르기까지 다양한 기기 환경에서 실행되는 새로운 비전 언어 모델(VLM)을 출시했다.
리퀴드 AI는 22일(현지시간) 독자 아키텍처 기반의 새로운 VLM 'LFM2-VL-3B'를 공개했다.
이 모델은 기존 4억5000만(450M), 16억(1.6B) 매개변수 모델을 확장한 30억(3B) 매개변수 버전으로, 이미지와 텍스트를 입력해 텍스트를 출력하는 작업에 최적화됐다.
 |
'액체 신경망'으로 유명한 리퀴드 AI가 휴대폰과 노트북, 단일 GPU 인스턴스부터 웨어러블 및 기타 임베디드 기기에 이르기까지 다양한 기기 환경에서 실행되는 새로운 비전 언어 모델(VLM)을 출시했다.
리퀴드 AI는 22일(현지시간) 독자 아키텍처 기반의 새로운 VLM 'LFM2-VL-3B'를 공개했다.
이 모델은 기존 4억5000만(450M), 16억(1.6B) 매개변수 모델을 확장한 30억(3B) 매개변수 버전으로, 이미지와 텍스트를 입력해 텍스트를 출력하는 작업에 최적화됐다.
LFM2 아키텍처 특유의 빠른 처리 속도를 유지하면서 정확도를 향상한 것이 특징이다. 모델은 LEAP과 허깅페이스에서 오픈 소스로 제공된다.
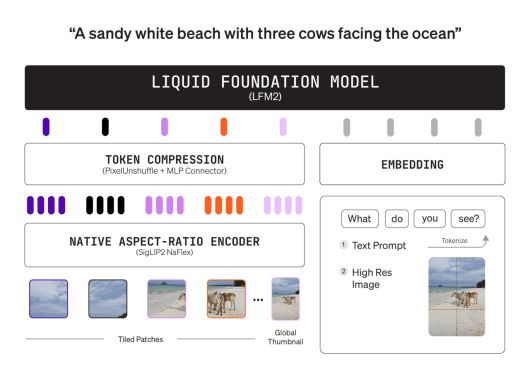
LFM2-VL-3B의 구조는 언어 타워(Language Tower), 비전 타워(Vision Tower), 프로젝터(Projector) 세 부분으로 나뉜다.
언어 타워는 'LFM2-2.6B'를 기반으로 한 컨볼루션 및 어텐션 하이브리드 구조를 사용한다. 비전 타워는 4억 매개변수 규모의 'SigLIP2 NaFlex'를 적용, 이미지의 종횡비를 그대로 유지하며 왜곡을 막는다. 프로젝터는 2층 MLP와 픽셀 언셔플(pixel unshuffle) 기술로 이미지 토큰을 압축한 뒤 언어 공간과 통합 처리, 사용자는 재학습 없이 비전 토큰 사용량을 조절할 수 있다.
인코더는 최대 512×512 해상도의 이미지를 처리할 수 있으며, 더 큰 이미지는 겹치지 않는 512×512 패치로 나눠 처리한다. 섬네일 경로를 사용해 패치로 나눌 때도 전체 이미지의 전반적인 정보를 파악할 수 있다. 예를 들어, 256×384 크기의 이미지는 96개의 토큰으로, 1000×3000 이미지는 1020개의 토큰으로 변환된다. 사용자는 최소·최대 이미지 토큰 수와 타일링 옵션을 조절해 모델 추론 속도와 이미지 처리 품질을 최적화할 수 있다.
LFM2-VL-3B는 단계적 학습 전략을 사용한다. 먼저 텍스트와 이미지의 비율을 조정하는 중간 학습을 진행하고, 이후 이미지 이해 능력을 높이기 위한 감독 미세조정(SFT)을 수행한다. 학습에는 대규모 오픈 데이터셋과 자체 제작한 합성 데이터가 활용된다.
 |
주요 벤치마크에서 LFM2-VL-3B는 경량 오픈 VLM 중 경쟁력 있는 성능을 기록했다.
'MM-IFEval' 51.83, '리얼월드QA' 71.37, 'MM벤치' 79.81, 'POPE' 89.01이며, 언어 이해 능력은 LFM2-2.6B과 유사한 'GPQA' 30%, 'MMLU' 63%를 기록했다.
모델은 영어, 일본어, 프랑스어, 스페인어, 독일어, 이탈리아어, 포르투갈어, 아랍어, 중국어, 한국어 등 다국어 시각 이해도 지원한다.
LFM2-VL-3B의 아키텍처는 계산량과 메모리를 소형 장치 수준으로 줄여주며, 이미지 토큰을 압축하고 사용량을 조절할 수 있어 예측 가능한 처리 속도를 제공한다. SigLIP2 400M NaFlex 인코더는 이미지의 종횡비를 유지해 세밀한 시각적 인식을 가능하게 하고, 프로젝터는 토큰 수를 줄여 초당 처리량을 높인다.
또 연구진은 GGUF 빌드를 공개해 로컬 장치에서도 모델을 구동할 수 있도록 지원하며, 로보틱스, 모바일, 산업용 등 현지 처리와 엄격한 데이터 관리가 필요한 환경에서도 활용할 수 있도록 설계됐다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>

![[종합] '희귀병 투병' 박원숙, 결국 안타까운 소식 전했다…"몸 너무 안 좋아" 오열 ('같이삽시다')](/_next/image?url=https%3A%2F%2Fthumb.zumst.com%2F256x144%2Fhttps%3A%2F%2Fstatic.news.zumst.com%2Fimages%2F77%2F2025%2F12%2F23%2F0d4010d8ca6e4487876aa066676ec256.jpg&w=384&q=100)





























































