
 |
[디지털데일리 김문기 기자] 인텔이 AI PC와 관련해 기존 인공지능이 사용자의 요청에 반응하는 보조 도구였다면 ‘에이전틱 AI(Agentic AI)’를 통해 스스로 인식하고, 추론하며, 행동하는 자율형 지능 구조를 지향한다고 강조했다.
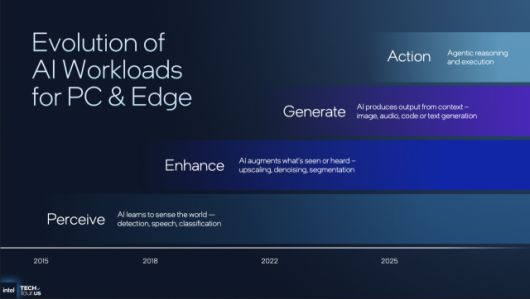
인텔은 최근 개최된 테크 투어 2025의 ‘에이전틱 AI 온 PC(Agentic AI on PCs)’ 세션에서 AI PC의 발전 단계를 시대별로 정리했다. 2015년은 인식(Perceive), 2018년은 향상(Enhance), 2022년은 생성(Generate)에 초점이 맞춰졌다면, 2025년은 여기에 행동(Action)과 추론(Reason)이 더해진 완전한 자율형 AI 단계로 진입한다는 것이다.
 |
이 변화의 배경에는 팬서레이크(Panther Lake)가 있다는게 인텔의 설명이다. 인텔은 차세대 프로세서를 중심으로 CPU, GPU, NPU의 하드웨어 성능과 오픈VINO, 윈도우 ML, ONNX 런타임 같은 소프트웨어 스택을 통합해 AI가 단순 추론을 넘어 스스로 문맥을 이해하고 판단하는 로컬 에이전트(Local AI Agent) 구조를 구현했다.
인텔은 이를 ‘에이전틱 스택(Agentic Stack)’이라 불렀다. 이 구조는 사용자의 명령을 단순히 수행하는 수준을 넘어, 목표를 분석하고 여러 하위 에이전트에 역할을 분배해 작업을 완성한다. 인텔이 설명한 오케스트레이션(Orchestration) 구조에서는 사용자의 요청을 총괄하는 오케스트레이터가 이를 슈퍼 에이전트(Super Agent)로 전달하고, 슈퍼 에이전트는 내부의 MCP 서버와 하위 도구를 순차적으로 호출한다.
MCP는 멀티 컴포넌트 프로토콜(Multi-Component Protocol)의 약자로, 챗PPT, 오픈인브라우저(OpenInBrowser), 슬라이즈메이커(SlidesMaker) 등 다양한 실행 모듈을 포함한다. 예를 들어 사용자가 “AI PC 시장 분석을 영어 슬라이드로 작성해 달라”고 요청하면, 슈퍼 에이전트가 슬라이즈메이커 모듈을 불러와 자료를 구성하고 챗GPT 서버에서 문서를 생성한 뒤, 오픈인브라우저를 통해 결과를 사용자에게 보여주는 방식이다.
이 과정은 인간의 추가 명령 없이 반복 수행된다. 인텔은 이를 ‘리피트 틸 돈(Repeat till done)’이라고 부르며, 사용자는 단 한 번의 프롬프트만 입력하면 된다. AI가 스스로 목표를 세우고, 계획을 수정하며, 실행과 검증을 반복하는 구조다. 클라우드 서버의 연산을 빌리지 않아도 로컬 단에서 완결된 업무 처리가 가능하다.
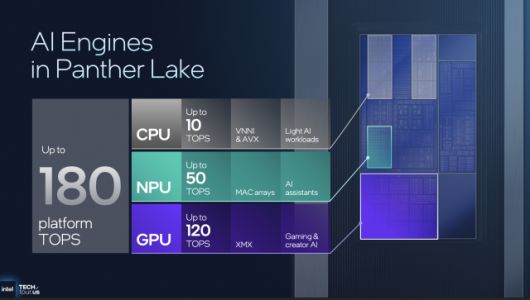
하드웨어 측면에서 팬서레이크는 이러한 로컬 지능 구조의 기반이 된다. CPU의 VNNI와 AVX 확장은 최대 10TOPS, NPU는 50TOPS, Xe3 GPU는 120TOPS의 연산 성능을 제공해 총 180TOPS 규모의 AI 처리 능력을 갖춘다. 각 하드웨어는 역할이 분담돼 있다. CPU는 경량 추론, NPU는 어시스턴트형 모델, GPU는 생성형 AI 워크로드를 담당한다.
 |
인텔이 말하는 에이전틱 AI는 단일 모델의 성능 경쟁이 아니라, 여러 에이전트가 협업하는 네트워크 구조로 진화하고 있다. 인텔은 이를 로컬 에이전트 네트워크(Local Agent Networks)라 정의하며, 단순히 반응하는(Reactive) 어시스턴트에서 스스로 판단하고 계획을 세우는(Proactive) 단계로의 전환이라고 설명했다. 사용자의 요청에 답하는 수준을 넘어, AI가 스스로 목적을 정의하고 이를 달성하기 위해 다른 에이전트와 협력하는 체계다.
결과적으로 이러한 구조적 변화는 인텔이 강조해온 ‘로컬 실행(Local Execution)’ 철학을 기반으로 한다. 데이터가 클라우드로 전송되지 않아 보안이 강화되고, 응답 지연도 줄어든다. 팬서레이크는 하드웨어 기반, OpenVINO는 실행 기반, 에이전틱 프레임워크는 지능 계층이라는 삼각 구조로, 인텔이 추구하는 AI PC 생태계의 형태를 구성한다.
- Copyright ⓒ 디지털데일리. 무단전재 및 재배포 금지 -
![“포옹하고 입맞춰”…유명 트로트 여가수, 상간 소송 피소 중에도 방송 출연 '충격' (사건반장)[종합]](/_next/image?url=https%3A%2F%2Fthumb.zumst.com%2F256x144%2Fhttps%3A%2F%2Fstatic.news.zumst.com%2Fimages%2F108%2F2025%2F12%2F29%2Fd268a48823d44c0db3a07b48827ab4f4.jpg&w=384&q=100)






























































