
 |
클리어워터 포레스트(Clearwater Forest)는 인텔의 서버용 E코어 설계가 성숙 단계에 이르렀음을 보여주는 프로세서다. 이 제품은 전 세대 시에라 포레스트(Sierra Forest)의 크레스트몬트(Crestmont) 코어를 계승하면서도, 내부 실행 파이프라인과 캐시 계층, 전력 관리 방식이 전면 재구성됐다. 그 중심에는 인텔이 ‘다크몬트(Darkmont)’라 부르는 차세대 효율 코어가 자리한다.
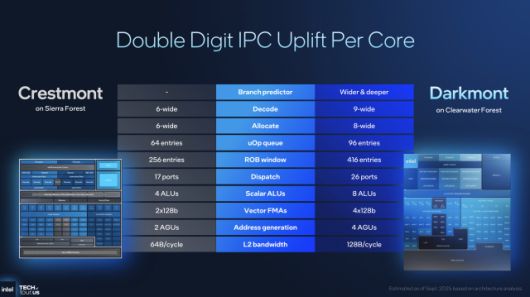 |
다크몬트 코어의 구조는 효율을 극한까지 끌어올리기 위해 정교하게 설계됐다. 프런트엔드는 9-와이드 디코더(Decoder) 구조를 채택해, 이전 세대 대비 50% 더 많은 명령어를 병렬로 디코드할 수 있다. 이는 단순한 폭 확장이 아니라, 비순차 실행(Out-of-Order Execution) 단계에서 명령어 병렬성을 극대화하기 위한 토대다. 재정렬 버퍼(Reorder Buffer)는 416엔트리까지 확장됐으며, 스케줄러(Scheduler) 역시 256개의 엔트리로 증가했다. 덕분에 동일 주파수에서도 명령어 투입·실행·커밋(Commit) 속도가 한층 높아졌다.
실행 포트는 총 26개로 확장됐다. 산술논리연산(ALU), 부동소수점(FPU), 벡터(FMA) 포트를 분리 배치해 명령 충돌을 줄였다. 특히 부동소수점 유닛은 FP32·FP16 연산을 동시에 수행할 수 있도록 재설계됐고, 정수 유닛에는 벡터 확장(VNNI, Vector Neural Network Instructions) 명령어가 추가되어 AI 추론 연산의 처리 효율을 높였다. 메모리 접근 단계에서는 2단 로드/스토어 버퍼 구조(Dual Load/Store Buffer) 가 도입되어 메모리 접근 대기 시간을 15% 단축시켰다. 인텔은 이 조합으로 클리어워터 포레스트의 IPC(Instructions Per Cycle)가 시에라 포레스트 대비 평균 17%, 전력 효율은 23% 향상됐다고 밝혔다.
코어당 캐시 구조도 병목 구간을 제거하는 방향으로 변화했다. 다크몬트 클러스터는 4MB L2 캐시를 공유하며, 각 코어는 독립된 2MB 프라이빗 L1 캐시를 갖는다. 상위에는 베이스 타일(Base Tile)에 통합된 192MB의 L3 캐시가 존재하며, 여러 타일 간 L3는 EMIB(Embedded Multi-die Interconnect Bridge)를 통해 링 버스 형태로 연결된다. L3 접근 지연은 시에라 포레스트 대비 약 30% 감소했고, 대역폭은 1.4배로 증가했다. 이러한 구조적 변화는 고밀도 AI 추론이나 클라우드 네이티브 워크로드처럼 메모리 레이턴시에 민감한 작업에서 결정적 효과를 발휘한다.
메모리 서브시스템은 12채널 DDR5-8000을 지원하며, 차세대 CXL 2.0(Coherent Express Link) 인터페이스가 기본 내장됐다. CXL을 통해 CPU와 GPU, 메모리 익스팬더 간 데이터 이동이 일관성(Coherency)을 유지한 채 수행되며, 이때의 왕복 지연시간은 120ns 미만이다. 기존 PCIe 기반 연결보다 45% 낮은 수치다. 인텔은 이를 ‘워크로드 연합성(Workload Cohesion)’이라 표현하며, CPU와 가속기가 동일한 메모리 주소 공간을 공유함으로써 데이터 복제나 버퍼링 과정이 사라진다고 설명했다.
 |
이러한 물리적 효율은 랙 단위 성능으로 직결된다. 인텔은 내부 데이터센터 테스트에서 클리어워터 포레스트 기반 랙이 기존 제온 서버 8대를 대체할 수 있음을 입증했다. 동일한 랙 공간에서 연산 성능은 3.5배, 가상 CPU(vCPU) 밀도는 2.3배 향상됐고, 전력 소비는 최대 750kW 감소했다. 이는 단일 서버 차원을 넘어, 데이터센터 전반의 운영비용(TCO, Total Cost of Ownership)을 구조적으로 줄이는 효과로 이어진다.
패키징 측면에서도 클리어워터 포레스트는 인텔의 최신 기술이 총집약된 형태다. 포베로스 다이렉트(Foveros Direct)와 EMIB가 결합된 3D 하이브리드 구조는 칩 간 통신 대역폭을 최대 10.5Tbps로 확장시켰다. EMIB는 실리콘 브리지 방식으로 각 타일을 연결하며, 구리-구리(Cu-Cu) 본딩 기반의 포베로스 다이렉트는 기존 마이크로 범프(Micro-bump) 대비 전력 손실을 40% 줄였다. 결과적으로 클리어워터 포레스트는 18A 공정에서 구현 가능한 최적의 다이 스태킹 사례로 꼽힌다.
보안 기능 역시 서버용 아키텍처답게 강화됐다. 클리어워터 포레스트는 인텔 TDX(Trust Domain Extensions)와 SGX(Software Guard Extensions)를 기본 탑재하고, 키 암호화 모듈(KEM, Key Encryption Module)을 하드웨어 계층에 통합했다. 여기에 인텔의 새로운 암호 알고리즘 가속기(Crypto Algorithm Accelerator)가 SHA-512, SM3, SM4, AES-GCM 등을 실시간 처리한다. 이는 금융·클라우드 환경에서 데이터 암호화 부하를 최대 65% 경감시키는 역할을 한다.
다크몬트 코어는 또한 AI 추론 전용 명령어 세트를 포함하고 있다. 인텔은 이를 “AVX-VNNI Light”로 표현하며, E코어에서도 AI 추론의 가속을 가능케 하는 확장 명령 세트라고 설명했다. 인텔 내부 테스트에서 BERT-Large 모델의 FP8 추론 성능은 시에라 포레스트 대비 1.8배, 스테이블 디퓨전(Stable Diffusion)의 이미지 생성 워크로드는 2.1배 향상된 것으로 보고됐다.
 |
클리어워터 포레스트(Clearwater Forest)는 인텔의 패키징 혁신이 실제 서버 설계에 어떻게 녹아드는지를 보여주는 대표적 사례로 볼 수 있다. 인텔은 이번 세대에서 EMIB(Embedded Multi-die Interconnect Bridge)와 포베로스 다이렉트(Foveros Direct)라는 두 가지 3D 패키징 기술을 결합해, 다중 타일 구조를 하나의 논리적 SoC처럼 통합했다. 그 결과, 코어와 캐시, 메모리 컨트롤러, I/O 인터페이스가 물리적으로 분리되어 있으면서도 단일 다이처럼 작동한다.
포베로스 다이렉트는 구리 대 구리(Cu-to-Cu) 본딩 방식을 기반으로 한다. 전통적인 마이크로 범프를 사용하지 않기 때문에 패키지 높이가 줄어들고, 신호 전달 저항이 극적으로 감소했다. 인텔은 이 기술을 “실리콘-실리콘 직접 결합”이라 부르며, 데이터 이동 효율을 0.05피코줄(pJ/bit) 수준으로 낮췄다고 밝혔다. EMIB는 이 포베로스 다이렉트 구조의 수평 확장을 담당한다. 실리콘 브리지 형태로 여러 타일을 연결해 다중 다이 간 신호를 전송하며, 이때의 총 대역폭은 10.5Tbps에 달한다. 이러한 조합 덕분에 클리어워터 포레스트는 CPU·메모리·I/O 간 신호 지연을 최소화한 완전 모듈형 서버 프로세서로 완성됐다.
이 다층 구조의 핵심은 베이스 타일(Base Tile)이다. 베이스 타일은 전체 시스템의 전력 분배망(PDN, Power Delivery Network)과 메모리 컨트롤러, L3 캐시 블록이 통합된 영역이다. 클리어워터 포레스트는 18A 공정 기반의 파워비아(PowerVia) 기술을 통해 전력선을 칩 후면으로 재배치함으로써, 베이스 타일 상단의 신호층 밀도를 높였다. 덕분에 EMIB를 통해 연결되는 컴퓨트 타일(Compute Tile) 간 신호 전송이 기존 대비 30% 이상 빨라졌고, 전력 효율은 25% 개선됐다.
클리어워터 포레스트의 각 컴퓨트 타일은 24개의 다크몬트(Darkmont) E코어와 4MB L2 캐시를 포함한다. 최대 12개의 컴퓨트 타일이 베이스 타일 위에 적층되며, 모든 타일은 링 버스(Ring Bus) 구조로 연결된다. 캐시 일관성을 유지하기 위해 인텔은 새로운 MESIF(Modified, Exclusive, Shared, Invalid, Forward) 프로토콜을 확장해, 각 타일 간 캐시 요청을 병렬 처리하도록 했다. 이로써 코어 간 데이터 접근 지연은 시에라 포레스트 대비 28% 감소했다.
플랫폼 인터페이스 측면에서, 클리어워터 포레스트는 최대 136개의 PCIe Gen5 레인과 12채널 DDR5-8000 메모리를 지원한다. 여기에 CXL 2.0(Coherent Express Link) 포트를 기본 제공해, CPU와 GPU, 메모리 익스팬더 간 메모리 일관성을 유지할 수 있다. 이를 통해 데이터 복제 없이 동일한 메모리 블록을 공유할 수 있으며, 결과적으로 시스템 메모리 효율이 45% 향상된다. UPI(Universal Processor Interconnect) 링크는 최대 24GT/s로 동작하며, 멀티소켓 구성에서도 1마이크로초 미만의 지연시간을 유지한다.
 |
보드 수준에서는 전력·신호 무결성(SI/PI) 개선이 이뤄졌다. 18A 공정의 파워비아 기반 전력망은 전압 강하(Voltage Droop)를 20% 줄였고, 이를 통해 CPU가 부하 변화에 즉각적으로 대응할 수 있다. 또한 인텔의 전력 텔레메트리 시스템(Application Energy Telemetry)은 워크로드 단위 전력 사용량을 모니터링하여, 실시간으로 클럭·전압 조정을 수행한다. 이 기능은 소켓 단위 제어를 넘어, 타일 단위의 전력 스케줄링까지 확장됐다.
이처럼 EMIB, 포베로스 다이렉트, 파워비아가 삼중으로 결합된 구조는 클리어워터 포레스트를 단순한 CPU가 아닌 하나의 패키징 플랫폼(Platform-in-a-Package)으로 만든다. 하드웨어 밀도를 유지하면서도 전력, 열, 신호 효율을 모두 확보한 구조 덕분에 클리어워터 포레스트는 18A 공정의 기술적 완성도를 상징하는 첫 번째 서버 아키텍처로 남게 됐다.
한마디로 클리어워터 포레스트는 인텔의 IDM 2.0 전략이 지향하는 최종 형태, 즉 설계·공정·패키징·플랫폼을 하나의 생태계 안에서 통합한 사례다.
- Copyright ⓒ 디지털데일리. 무단전재 및 재배포 금지 -



!['조폭 연루설' 조세호, '연예대상'엔 없고 '1박 2일'엔 있었다…하차 전 '無 편집' 등장 [엑's 이슈]](/_next/image?url=https%3A%2F%2Fthumb.zumst.com%2F256x144%2Fhttps%3A%2F%2Fstatic.news.zumst.com%2Fimages%2F108%2F2025%2F12%2F22%2F74a0e8e07e8d4f43bd26149bc1aa903e.jpg&w=384&q=100)



























































